BASNet

Boundary-Aware Salient Object Detection 即边界感知显著目标检测
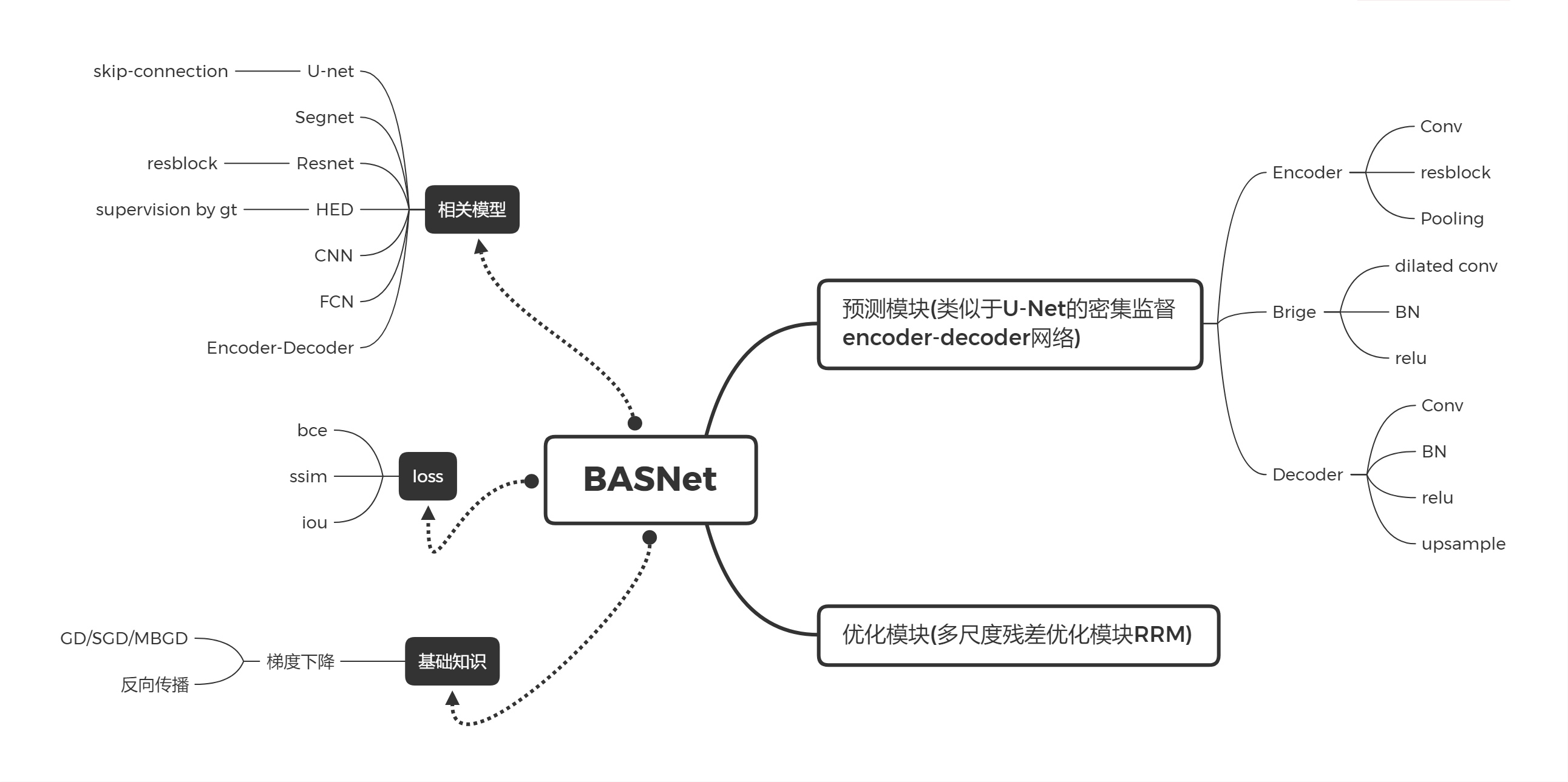
根据放假以来的学习,简单画了下理解网络所需要理解掌握的知识。自己还没有摸太清,只是目前理解的,待更新…
BASNet
基础知识
梯度下降
GD MBGD SGD区别:
https://www.cnblogs.com/lliuye/p/9451903.html
? SGD为什么能逃脱鞍点:
https://blog.csdn.net/bl128ve900/article/details/94293284
softmax
我们知道max,假如说我有两个数,a和b,并且a>b,如果取max,那么就直接取a,没有第二种可能但有的时候我不想这样,因为这样会造成分值小的那个饥饿。所以我希望分值大的那一项经常取到,分值小的那一项也偶尔可以取到,那么我用softmax就可以了 现在还是a和b,a>b,如果我们取按照softmax来计算取a和b的概率,那a的softmax值大于b的,所以a会经常取到,而b也会偶尔取到,概率跟它们本来的大小有关。所以说不是max,而是 Soft max 那各自的概率究竟是多少
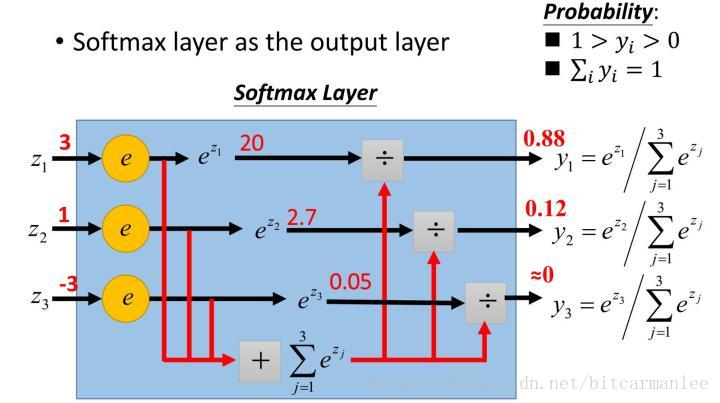
softmax不仅把神经元输出构造成概率分布,而且还起到了归一化的作用,适用于很多需要进行归一化处理的分类问题。
?以softmax为激励函数交叉熵Loss函数的求导过程
https://www.iteye.com/blog/kissmett-2440592
https://blog.csdn.net/bitcarmanlee/article/details/82320853
这个不懂 留坑了
BN
Batch Normalization批标准化
https://www.cnblogs.com/guoyaohua/p/8724433.html
BatchNorm就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
白化,就是对输入数据分布变换到0均值,单位方差的正态分布
Relu与BN层顺序问题
这是我比较疑惑的问题,看到网络模型中Conv+BN+ReLU层,根据Batch Normalization,下一层输入不是应该保持相同分布更好吗,为什么不先进行激活再标准化下一层输入呢….
https://www.cnblogs.com/zi-wang/p/12295529.html
https://zhuanlan.zhihu.com/p/113442866?from_voters_page=true
https://www.zhihu.com/question/318354788
现在网络一般默认用BN-ReLu
Batch Norm方法经过规范化和缩放平移,可以使输入数据,重新回到非饱和区,还可以更进一步:控制激活的饱和程度,或是非饱和函数抑制与激活的范围。
sigmoid
看到源码里BASNET中最后return的是几个side-output的sigmoid值不理解,留坑
相关模型
CNN
卷积神经网络是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,其三个关键的操作,其一是局部感受野,其二是权值共享,其三是pooling层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
网络架构
卷积神经网络结构包括:卷积层,降采样层,全链接层。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。
卷积神经网络是一种多层的监督学习神经网络,隐含层的卷积层和池采样层是实现卷积神经网络特征提取功能的核心模块。该网络模型通过采用梯度下降法最小化损失函数对网络中的权重参数逐层反向调节,通过频繁的迭代训练提高网络的精度。==卷积神经网络的低隐层是由卷积层和最大池采样层交替组成,高层是全连接层对应传统多层感知器的隐含层和逻辑回归分类器。==第一个全连接层的输入是由卷积层和子采样层进行特征提取得到的特征图像。最后一层输出层是一个分类器,可以采用逻辑回归,Softmax回归甚至是支持向量机对输入图像进行分类。
卷积
卷积的目的:为了从输入图像中提取特征。卷积可以通过从输入的一小块数据中学到图像的特征,并可以保留像素间的空间关系。
滤波器filter(卷积核kernel)的运算
卷积运算细节:https://blog.csdn.net/dcrmg/article/details/79652487
对于同样的输入图像,不同值的滤波器将会生成不同的特征图。
通过在卷积操作前修改滤波矩阵的数值,我们可以进行诸如边缘检测、锐化和模糊等操作 —— 这表明不同的滤波器可以从图中检测到不同的特征,比如边缘、曲线等。
卷积核里面的参数,一开始是随机数,它本身是需要训练的权重值,只是一开始被初始化了为随机数,并不是一直都是随机数,它会随着网络的训练,逐渐发生变化,最后生成固定的权重值。
卷积核与通道数的关系
https://segmentfault.com/q/1010000016667038
看网络架构的时候很懵,回来补一下基础。
卷积核数与输出通道数是相等的,且可以自定义,取决于自己的实验设置。
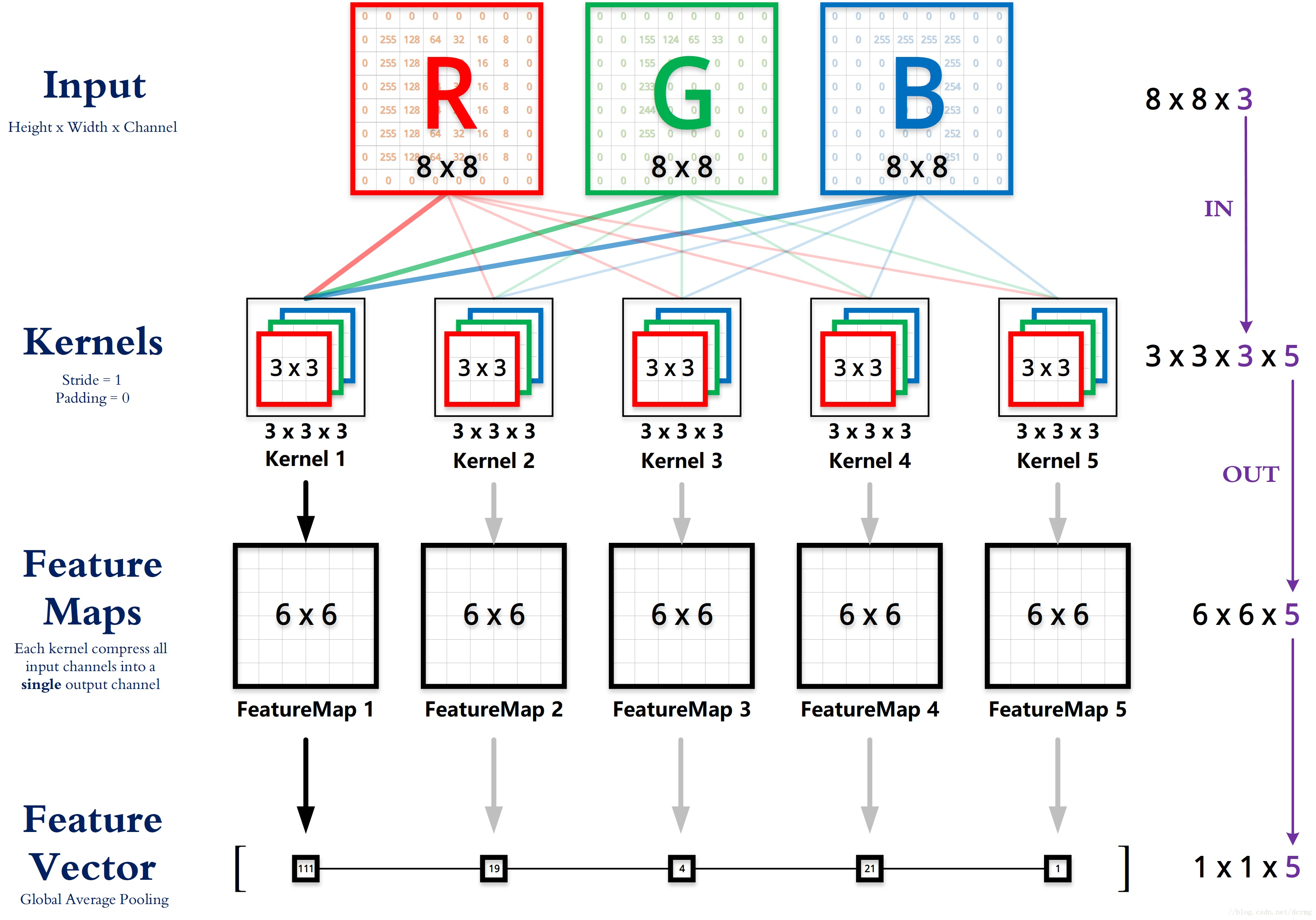

特征图
通过在图像上滑动滤波器并计算点乘得到矩阵叫做“卷积特征(Convolved Feature)”或者“激活图(Activation Map)”或者“特征图(Feature Map)”。
特征图的大小(卷积特征)由三个参数控制:深度(depth)、步长(stride)、零填充(zero-padding)。
深度:深度对应的是卷积操作所需的滤波器个数。在下图的网络中,我们使用三个不同的滤波器对原始图像进行卷积操作,这样就可以生成三个不同的特征图。你可以把这三个特征图看作是堆叠的 2d 矩阵,那么,特征图的“深度”就是三。
 步长:步长是我们在输入矩阵上滑动滤波矩阵的像素数。当步长为 1 时,我们每次移动滤波器一个像素的位置。当步长为 2 时,我们每次移动滤波器会跳过 2 个像素。步长越大,将会得到更小的特征图。
步长:步长是我们在输入矩阵上滑动滤波矩阵的像素数。当步长为 1 时,我们每次移动滤波器一个像素的位置。当步长为 2 时,我们每次移动滤波器会跳过 2 个像素。步长越大,将会得到更小的特征图。
零填充:有时,在输入矩阵的边缘使用零值进行填充,这样我们就可以对输入图像矩阵的边缘进行滤波。零填充的一大好处是可以让我们控制特征图的大小。使用零填充的也叫做泛卷积,不适用零填充的叫做严格卷积。(padding用于提取边缘特征,解决图像边缘信息损失的问题)
感受野
感受野,即一个像素对应回原图的区域大小
在卷积神经网络中,感受野(Receptive Field)的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域,如图1所示。

感受野计算公式
关于感受野大小的计算方式是采用从最后一层往下计算的方法,即先计算最深层在前一层上的感受野,然后逐层传递到第一层,使用的公式可以表示如下:
其中,
池化
Pooling 的本质,其实是采样。Pooling 对于输入的 Feature Map,选择某种方式对其进行压缩。
对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征。
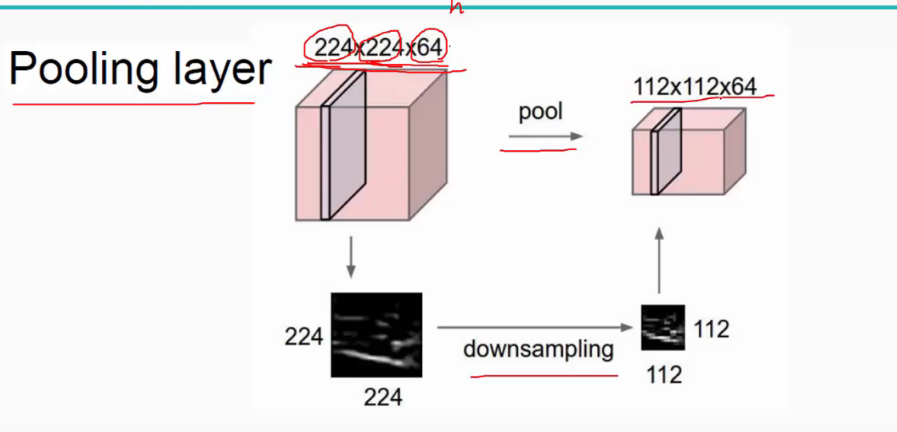
Max Pooling的作用
https://www.cnblogs.com/guoyaohua/p/8674228.html
1.invariance(不变性),这种不变性包括translation(平移),rotation(旋转),scale(尺度)
2.扩大感受野
首先它第一个作用是降低feature map的尺寸,减少需要训练的参数;其次,因为有缩小的作用,所以之前的4个像素点,现在压缩成1个。那么,相当于透过这1个点,就可以看到前面的4个点。
卷积与池化的区别
看到这里我有一个疑问,卷积与池化同样是提取特征,在使用上什么区别呢?
1:卷积过程导致的图像变小是为了提取特征。卷积操作相当于经过特征提取,已经改变了卷积核区域大小的像素变化,重新组合成新特征像素了。
2:池化下采样是为了降低特征的维度,池化操作可以起到平移不变性,如4个像素经过池化选泽一个具有代表的像素,给相似特征一定弹性。
虽然结果都是图像或者特征图变小,但是目的是不一样的。池化下采样比较粗暴,可能将有用的信息滤除掉,而卷积下采样过程控制了步进大小,信息融合较好,现在池化操作较少的被采用。反卷积和上采样也同理。
卷积与池化特征图的计算
https://www.pianshen.com/article/30711004970/
卷积:
若图像为正方形:设输入图像尺寸为WxW,卷积核尺寸为FxF,步幅为S,Padding使用P,经过该卷积层后输出的图像尺寸为NxN:
若图像为矩形:设输入图像尺寸为WxH,卷积核的尺寸为FxF,步幅为S,图像深度(通道数)为C,Padding使用P,则:
卷积后输出图像大小:
输出图像的通道数=C
池化:
设输入图像尺寸为WxH,其中W:图像宽,H:图像高,D:图像深度(通道数),卷积核的尺寸为FxF,S:步长
池化后输出图像大小:
池化后输出图像深度为D
当进行池化操作时,步长S就等于池化核的尺寸,如输入为24x24,池化核为4x4,则输出为
若除不尽,则取较小的数,如池化核为7x7,则输出为
式子是怎么来的我还不太理解emm…
空洞卷积:
d为dilation(空洞率) p为padding k为kernel size
high-level与low-level feature
https://blog.csdn.net/nanhuaibeian/article/details/103305128
Low-level feature: 通常是指图像中的一些小的细节信息,例如边缘(edge),角(corner),颜色(color),像素(pixeles), 梯度(gradients)等,这些信息可以通过滤波器、SIFT或HOG获取
high-level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具有更丰富的语义信息
浅层的特征他的感受野较小,例如:他只从5x5的区域提取一个边缘信息。 high-level feature 他的感受野大, 他可以从100x100的区域总结一个语义信息。
空洞卷积
https://www.zhihu.com/question/54149221
空洞卷积(扩张卷积,带孔卷积,dilated convolution)
在图像分割领域,图像输入到CNN中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作),之前的pooling操作使得每个pixel预测都能看到较大感受野信息。
因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,不通过pooling也能有较大的感受野看到更多的信息可以使用dilated conv。
空洞卷积核kernel 并不连续,也就是并不是所有的 pixel 都用来计算了。
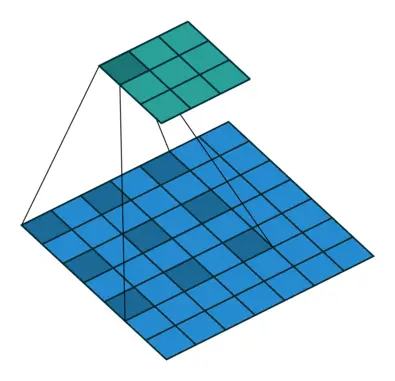
上图实际的卷积kernel size还是3x3,但是空洞为1,也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7。
dilation空洞率的计算
https://blog.csdn.net/chen1234520nnn/article/details/102516704
膨胀后卷积核尺寸 = 膨胀系数 * (原始卷积核尺寸 - 1) + 1
以卷积核3*3为例,膨胀系数为2,那么卷积核膨胀之后,卷积核的单边尺寸就变成了2*(3-1)+1,即卷积核的尺寸变成了5*5。
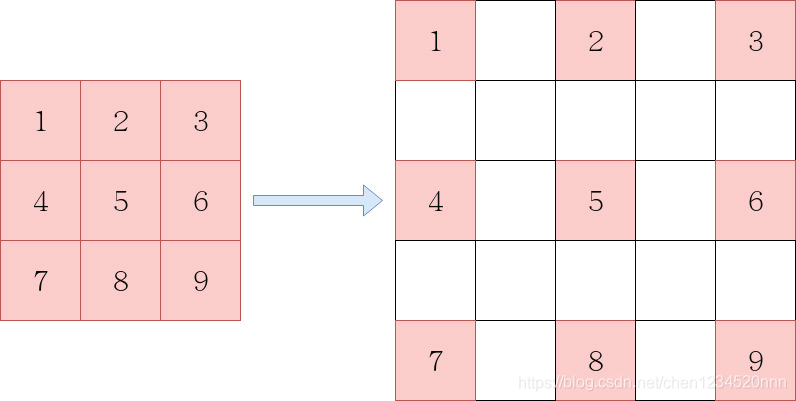
卷积核膨胀是将卷积核扩张到膨胀尺度约束的尺度中,并将原卷积核没有占用的区域填充零
FCN
paper:https://arxiv.org/abs/1411.4038
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。而FCN提出可以把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题。
上采样(Upsample)
在应用在计算机视觉的深度学习领域,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(e.g.:图像的语义分割),这个采用扩大图像尺寸,实现图像由小分辨率到大分辨率的映射的操作,叫做上采样(Upsample)。
上采样有3种常见的方法:双线性插值(bilinear),反卷积(Transposed Convolution),反池化(Unpooling)。
反卷积
https://blog.csdn.net/jasonleesjtu/article/details/89791528
https://www.zhihu.com/question/48279880
稀疏矩阵
在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
反卷积的操作只是恢复了输入矩阵的尺寸大小,并不能恢复输入矩阵的每个元素值。反卷积,也叫转置卷积,它并不是正向卷积的完全逆过程。
反卷积的输入输出尺寸关系为:![[公式]](/images/loading.svg)
双线性插值(bilinear upsampling)
FCN中上采样的过程用到的就是双线性插值法,双线性插值不需要学习任何的参数,通过人为的操作的。
用x和x0,x1的距离作为一个权重,用于y0和y1的加权。双线性插值本质上就是在两个方向上做线性插值。
https://blog.csdn.net/qq_37577735/article/details/80041586
U-net
https://segmentfault.com/a/1190000021798146
https://blog.csdn.net/hduxiejun/article/details/71107285
U-net的网络结构如下所示。左边为encoder部分,对输入进行下采样,下采样通过最大池化实现;右边为decoder部分,对encoder的输出进行上采样,恢复分辨率,上采样通过Upsample实现;中间为跳跃连接(Skip-connect),进行特征融合。由于整个网络形似一个”U”,所以称为U-net。
网络中除了最后的输出层,其余所有卷积层均为3 * 3卷积。
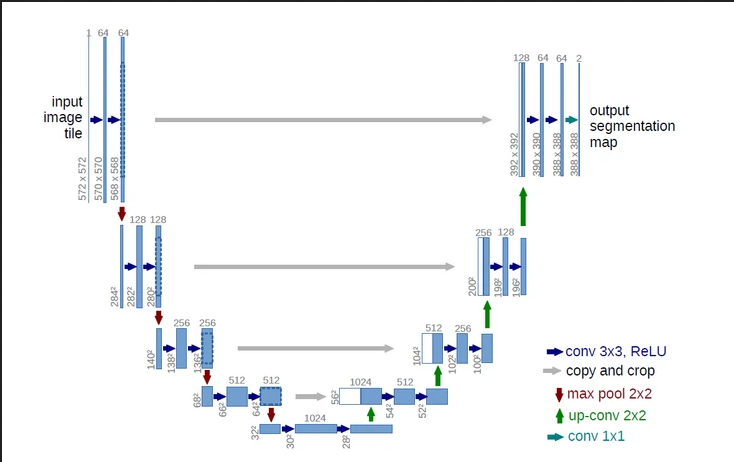
除了全连接层,使用卷积神经网络进行语义分割存在的另一个大问题是池化层。池化层不仅扩大感受野、聚合语境从而造成了==位置信息的丢失。==但是,语义分割要求类别图完全贴合,因此需要保留位置信息。
U-Net 采用编码器-解码器结构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。编码器和解码器之间通常存在快捷连接,因此能帮助解码器更好地修复目标的细节。
skip-connection
跳跃连接,通常用于残差网络中。(确实把U-net拉直成纵向排布可以看到Resnet中的跳跃连接)
在论文中叫拼接,在UNet有四个拼接操作。这一操作的目的是为了融合特征信息,融合了底层信息的位置信息与深层特征的语义信息,在拼接的时候要注意,不仅图片大小要一致(故要crop,是为了使图片大小一致)而且特征的维度(channels)也要才一样,才可以拼接。
具体来说,当网络完成反卷积之后,就会将反卷积的结果与Encoder中对应步骤的特征图拼接起来,需要注意的是,Encoder特征图尺寸稍大,将其修剪过后进行拼接。拼接会保留了更多的维度/位置 信息,这使得后面的 layer 可以在浅层特征与深层特征自由选择,这对语义分割任务来说更有优势
copy and crop中的copy就是concatenate而crop是为了让两者的长宽一致
Segnet
https://blog.csdn.net/zhuzemin45/article/details/79709874
paper:https://arxiv.org/abs/1511.00561
SegNet基于FCN,修改VGG-16网络得到的语义分割网络。
网络架构

SegNet和FCN思路十分相似,只是Encoder,Decoder(Upsampling)使用的技术不一致。最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类概率。
Resnet
解读:https://blog.csdn.net/csdnldp/article/details/78313087
https://blog.csdn.net/sunny_yeah_/article/details/89430124
https://www.bilibili.com/video/BV1T7411T7wa
解决了梯度弥散/爆炸问题和退化问题
在残差网络中,不是让网络直接拟合原先的映射,而是拟合残差映射。
原来提取出的特征是H(x),x就是估计值(也就是上一层ResNet输出的特征映射)。作者认为F(x)=H(x)-x的求解比H(x)的求解更简单。这样的话这一层的神经网络可以不用学习整个的输出,而是学习上一个网络输出的残差。
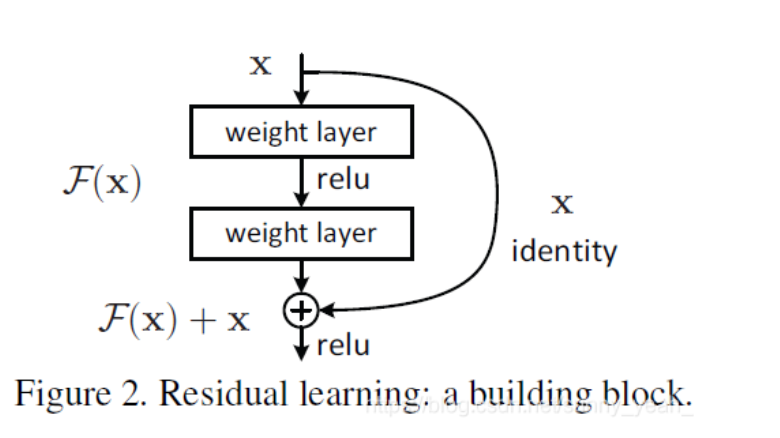
如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值。那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧?
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了?
当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
————————————————
版权声明:本文为CSDN博主「sunny_yeah_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sunny_yeah_/article/details/89430124
为什么层数多了准确率反而下降
参考资料:https://zhuanlan.zhihu.com/p/67860570
虽然56层网络的解空间包含了20层网络的解空间,但是我们在训练网络用的是随机梯度下降策略,往往解到的不是全局最优解,而是局部的最优解,显而易见56层网络的解空间更加的复杂,所以导致使用随机梯度下降算法无法解到最优解。
如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差比拟合恒等映射更加容易。
引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化
shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。 而且,整个网络可以依旧通过端到端的反向传播训练。
不同规格ResNet结构:
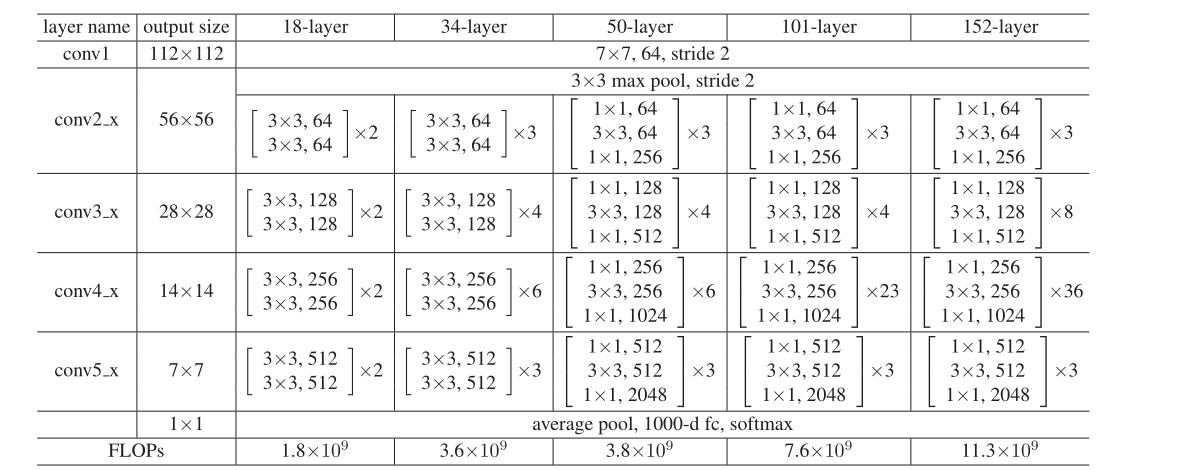
BasicBlock和Bottleneck
https://www.zhihu.com/question/413586557/answer/1402003639
在ResNet网络结构中会用到两种残差模块,一种是以两个3*3的卷积网络串接在一起作为一个残差模块,另外一种是1*1、3*3、1*1的3个卷积网络串接在一起作为一个残差模块。
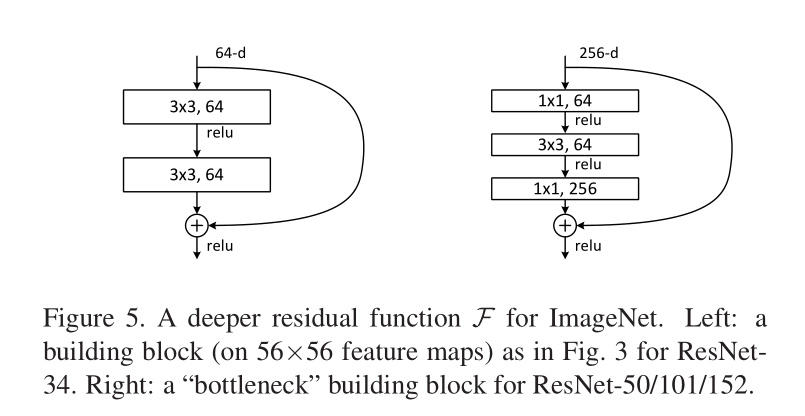
1*1卷积核的作用
https://blog.csdn.net/qq_27871973/article/details/82970640
看到Bottleneck中使用了1*1卷积核,好奇起什么作用
对二维矩阵来说,相当于直接乘以2

对三维矩阵来说
可以进行降维或者升维,也就是通过控制卷积核(通道数)实现,这个可以帮助减少模型参数,也可以对不同特征进行尺寸的归一化;同时也可以用于不同channel上特征的融合。
(?留坑了 三维不懂 所以Bottleneck也留坑)
HED
paper:https://arxiv.org/abs/1504.06375
参考资料:
https://blog.csdn.net/u014779538/article/details/92765963
https://blog.csdn.net/u012905422/article/details/52782615
https://zhuanlan.zhihu.com/p/35694372
supervised by gt这块不懂 留坑了
这部分感谢研究生姐姐的帮助,我不懂HED中多尺度特征与supervised by gt之间的关系,感谢细心的解答QAQ
ground truth
https://www.zhihu.com/question/22464082
在有监督学习中,数据是有标注的,以(x, t)的形式出现,其中x是输入数据,t是标注.正确的t标注是ground truth, 错误的标记则不是。
因此如果标注数据不是ground truth,那么loss的计算将会产生误差,从而影响到模型质量。
监督学习与无监督学习
多尺度特征
图像金字塔
https://www.cnblogs.com/sddai/p/10330756.html
https://zhuanlan.zhihu.com/p/94014493
图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。
一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。层级越高,则图像越小,分辨率越低。

高斯金字塔用来向下降采样图像(尺寸减半),而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像(图片尺寸加倍)。
高斯金字塔
在计算机视觉与图像处理相关任务中,经常需要使用同一张图的不同尺寸的子图,我们可以使用高斯金字塔来获取这些子图。
下采样之前需要首先进行高斯滤波
高斯噪声与高斯滤波:https://blog.csdn.net/u013007900/article/details/78181249(?留坑了)
下采样可以通过抛去图像中的偶数行和偶数列来实现,这样图像长宽各减少二分之一,面积减少四分之一。opencv提供了pyrDown()函数用于下采样。
随着下采样的进行,图像的分辨率不断降低,视觉效果也越来越模糊。
拉普拉斯金字塔
拉普拉斯金字塔可以认为是残差金字塔,用来存储下采样后图片与原始图片的差异。高斯金字塔中任意一张图进行下采样再进行上采样后与原图存在差异,因为下采样过程丢失的信息不能通过上采样来完全恢复,也就是说下采样是不可逆的。
我们需要记录再次上采样得到Up(Down(Gi))与原始图片Gi之间的差异,这就是拉普拉斯金字塔的核心思想
拉普拉斯金字塔就是记录高斯金字塔每一级下采样后再上采样与下采样前的差异,目的是为了能够完整的恢复出每一层级的下采样前图像。

构建对应的拉普拉斯金字塔如下(第1级为高斯金字塔中最小尺寸的图,也就是高斯金字塔最后1级)

多尺度模型架构
https://zhuanlan.zhihu.com/p/74710464
(先留坑)
网络架构
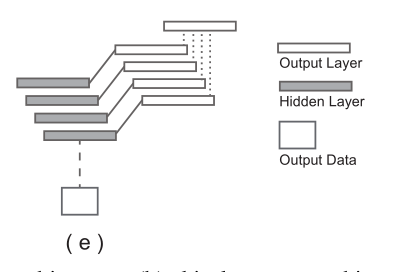
HED采用的多尺度特征结构。
Holistically :表示边缘预测结果是基于端对端的
Nested:生成的Edge过程中,将许多尺度不同的图片进行fusion得到结果
作者在VGG-Net的基础上进行修改,在每个卷积层的后边加入一层 side output layer,在每个side output layer 上进行deep supervision learning,有助于结果向边缘检测方向进行。每个side output layer 将得到一个edge map,如下图:
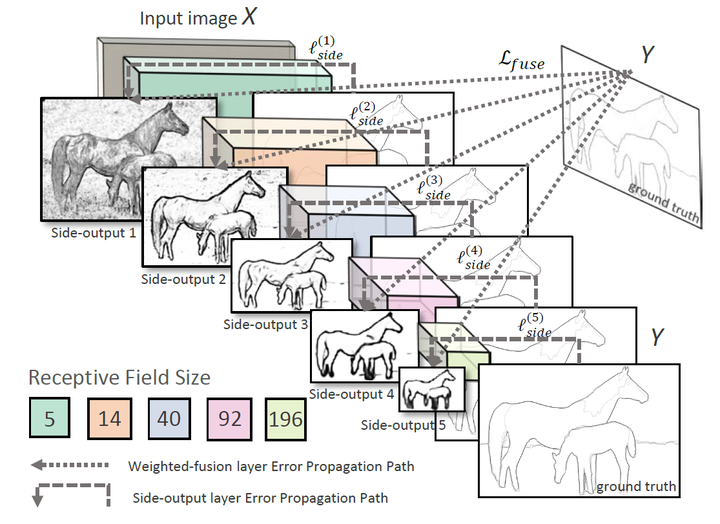
浅层越能检测出很细节的边缘信息,越深层越能体现一些语义分割上的信息,与ground truth 比较接近。最后通过一个fusion layer将各个edge map 进行融合,在这个fusion layer中对所有的edge map 都进行loss,以及bp等操作(multi-loss)。
在VGG-16的5个block的Max Pooling降采样之前,HED通过side_branch函数产生了5个分支,最后这5个side_branch的输出通过Concatenate操作合并在一起。网络的5个side_branch和一个fuse branch通过sigmoid激活函数后共同作为网络的输出,每个输出的尺寸均和输入图像相同。
还是不懂 代码也是- -留坑
loss
BCE
如何理解信息量、熵、相对熵、交叉熵:
https://blog.csdn.net/Lison_Zhu/article/details/97234817
BCE用于二分类
其中
链接中举出青蛙的例子浅显易懂,如果忘了可以回去看一遍。
SSIM(结构相似性)
SSIM是一种衡量两幅图片相似度的指标。
SSIM的输入就是两张图像,我们要得到其相似性的两张图像。其中一张是未经压缩的无失真图像(即ground truth),另一张就是你恢复出的图像。
假设输入的两张图像是x和y
α>0, β>0, γ>0
其中
c(x,y)=
s(x,y)=
其中l(x, y)是亮度比较,c(x,y)是对比度比较,s(x,y)是结构比较。
在实际工程计算中,我们一般设定
SSIM(x,y)=
总结:
- SSIM具有对称性,即SSIM(x,y)=SSIM(y,x)
- SSIM是一个0到1之间的数,越大表示输出图像和无失真图像的差距越小,即图像质量越好。当两幅图像一模一样时,SSIM=1
IOU
交并比,是目标检测中最常用的指标
可以反映预测检测框与真实检测框的检测效果
关于IOU/GIOU/DIOU/CIOU:
https://www.cnblogs.com/wujianming-110117/p/13019343.html
optimizer
标准动量优化算法(Momentum)
RMSProp算法
Adam算法
网络架构分析
有了上述基础知识和相关模型的了解,我们分析一下BASNET的架构。
目的是实现显著目标检测和物体分割
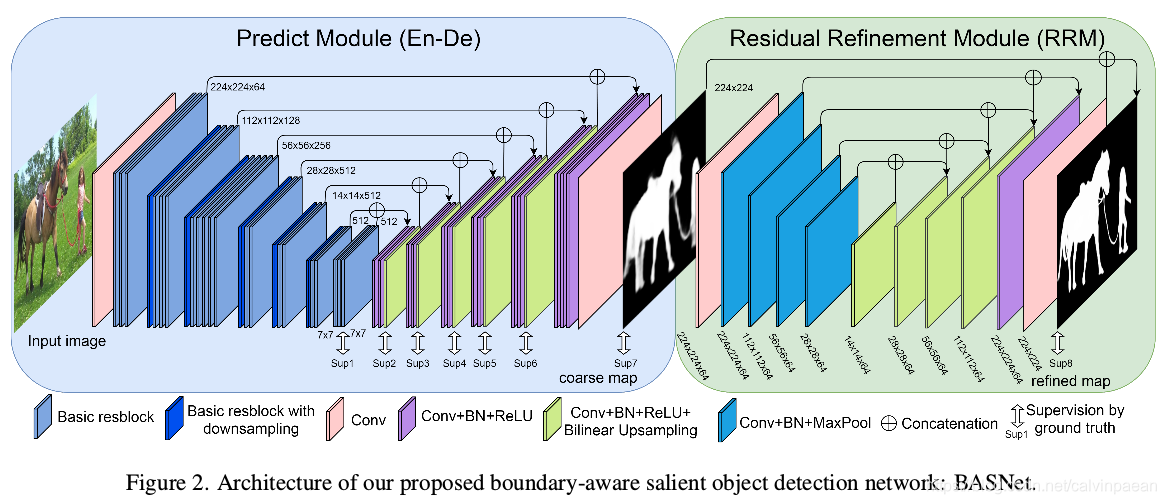
Predict Module
Encoder
Encoder部分包含一个输入卷积层和六个由基本残差模块组成的stage。输入卷积层和前4个stages都是使用ResNet-34的层。
ResNet34架构:

各层参数如下:
1.输入卷积层
| Resnet34 | BASNET | |
|---|---|---|
| input | 224×224× | 224×224× |
| kernel | 7×7,64 | 3×3,64 |
| padding | 3 | 1 |
| stride | 2 | 1 |
| output | 112×112×64 | 224×224×64 |
ResNet34 size减半而本论文中输入卷积层的特征图与输入图像有着相同的分辨率。
2.stage1
ResNet34有3x3,stride为2,padding为1的MaxPool
故经过MaxPool后 输出特征图为56x56。
而BASNet在输入层之后没有池化操作。
以下是一个ResBlock的参数,ResBlock_num=3。
| Conv | RESNET34 | BASNET |
|---|---|---|
| input | 56×56×64 | 224x224×64 |
| kernel | 3×3,64 | 3×3,64 |
| padding | 1 | 1 |
| stride | 1 | 1 |
| output | 56×56×64 | 224×224×64 |
经过三个ResBlock后,RESNet34 output=56×56×64,BASNet output=224×224×224
此时在BASNet中输出特征图与输入图像依然有着相同的分辨率。
这和原来的ResNet-34不同,它在第一个特征图的分辨率缩小到了 1 / 4大小。
这个改动使得网络在早期阶段就能够获取更高的分辨率特征图,也可以降低整体的感受野。
降低感受野有什么作用 感受野是增加还是降低有益:
如果感受野太小,则只能观察到局部的特征,如果感受野太大,则获取了过多的无效信息
3.stage2
ResBlock_num=4
| CONV | RESNET34 | BASNET |
|---|---|---|
| input | 56×56×64 | 224×224×64 |
| kernel | 3×3,128 | 3×3,128 |
| padding | 1 | 1 |
| stride | 第一个ResBlock为2,其余为1 | 第一个ResBlock为2,其余为1 |
| output | 28×28×128 | 112×112×128 |
4.stage3
ResBlock_num=6
| CONV | RESNET34 | BASNET |
|---|---|---|
| input | 28×28×128 | 112×112×128 |
| kernel | 3×3,256 | 3×3,256 |
| padding | 1 | 1 |
| stride | 第一个ResBlock为2,其余为1 | 第一个ResBlock为2,其余为1 |
| output | 14×14×256 | 56×56×256 |
5.stage4
ResBlock_num=3
| CONV | RESNET34 | BASNET |
|---|---|---|
| input | 14×14×256 | 56×56×256 |
| kernel | 3×3,512 | 3×3,512 |
| padding | 1 | 1 |
| stride | 第一个ResBlock为2,其余为1 | 第一个ResBlock为2,其余为1 |
| output | 7×7×512 | 28×28×512 |
为了获得和ResNet-34一样的感受野,我们在ResNet-34第4个stage之后增加了2个额外的stages。这两个stages都由3个基础的ResBlock构成,有512个filters。在此之前有一个大小为2、不重叠的max pool层。
6.stage5
| MAXPOOL | BASNET |
|---|---|
| input | 28×28×512 |
| kernel | 2×2 |
| padding | 0 |
| stride | 2 |
| output | 14×14×512 |
关于padding和stride的细节论文里好像没写(根据代码和计算推一下,可能有误…
ResBlock_num=3
| CONV | BASNET |
|---|---|
| input | 14×14×512 |
| kernel | 3×3,512 |
| padding | 1 |
| stride | 1 |
| output | 14×14×512 |
7.stage6
| MAXPOOL | BASNET |
|---|---|
| input | 14×14×512 |
| kernel | 2×2 |
| padding | 0 |
| stride | 2 |
| output | 7×7×512 |
ResBlock_num=3
| CONV | BASNET |
|---|---|
| input | 7×7×512 |
| kernel | 3×3,512 |
| padding | 1 |
| stride | 1 |
| output | 7×7×512 |
至此,Encoder部分结束,BASNet输出的特征图大小与ResNet34输出特征图大小相同。
通过对特征图的计算,我对卷积与池化操作的细节和代码参数更加了解,也理解了网络中图片尺寸的变化过程以及网络的架构。
Bridge
为了进一步捕捉到全局信息,在Encoder和Decoder之间添加brige。包含三个有512filter,dilation为2的空洞卷积,每个卷积层后跟随一个BN和ReLU。
| dila-conv | basnet |
|---|---|
| input | 7×7 |
| kernel | 3×3 |
| dilation | 2 |
| padding | 2 |
| stride | 1 |
| output | 7×7 |
Decoder
Decoder结构几乎与Encoder对称。每个stage包括三个卷积层,每个卷积层后跟随BN,ReLU。每个stage的input都是前一层upsample和在Encoder中对应层concatenate而成的。
为了生成特征图的side-output,将每个decoder stage和bridge stage的多通道输出作为一个普通的 3 × 3 卷积层的输入,后面跟着一个双线性上采样以及一个sigmoid 函数。因而,给定输入图像,我们的预测模块在训练过程中就产生7个特征图。
代码
pytorch学习
开发文档:https://pytorch.org/docs/stable/index.html
Tensors
https://zhuanlan.zhihu.com/p/347676809
Tensors张量是一种特殊的数据结构,它和数组还有矩阵十分相似。在Pytorch中,我们使用tensors来给模型的输入输出以及参数进行编码。 Tensors除了张量可以在gpu或其他专用硬件上运行来加速计算之外,其他用法类似于Numpy中的ndarrays。
1.创建方法
直接创建tensor/从numpy导入
2.属性
tensor.shape shape是关于tensor维度的一个元组,它决定了输出tensor的维数。
tensor.dtype 数据类型
tensor.device 存储设备
3.操作
操作见开发文档,它们都可以在GPU上运行
Autograd
https://zhuanlan.zhihu.com/p/347672836
神经网络(NNs)是作用在输入数据上的一系列嵌套函数的集合,这些函数由权重和误差来定义,被存储在PyTorch中的tensors中。 神经网络训练的两个步骤: 前向传播:在前向传播中,神经网络通过将接收到的数据与每一层对应的权重和误差进行运算来对正确的输出做出最好的预测。 反向传播:在反向传播中,神经网络调整其参数使得其与输出误差成比例。反向传播基于梯度下降策略,是链式求导法则的一个应用,以目标的负梯度方向对参数进行调整。
神经网络
:o:https://zhuanlan.zhihu.com/p/347678492
:o:https://blog.csdn.net/zkk9527/article/details/88399176(写的详细,适合新手阅读)
使用torch.nn包来构建神经网络.
一个nn.Module包含各个层和一个forward(input)方法,该方法返回output.
nn.Parameter-一种张量,当把它赋值给一个Module时,被自动的注册为参数.
神经网络的典型训练过程如下:
- 定义神经网络模型,它有一些可学习的参数(或者权重);
- 在数据集上迭代;
- 通过神经网络处理输入;
- 计算损失(输出结果和正确值的差距大小)
- 将梯度反向传播会网络的参数;
- 更新网络的参数,主要使用如下简单的更新原则:
weight = weight - learning_rate * gradient在参数初始化完成之后,可以通过以下四个关键步骤来定义和训练神经网络:前向传播->损失计算->反向传播->更新参数
1.建立网络与前向传播
如果你想做一个网络,需要先定义一个Class,继承 nn.Module
这个Class里面主要写两个函数,一个是初始化的__init__函数,另一个是forward函数。
先在初始化函数中定义 神经网络__init__里面就是定义卷积层,==当然先得super()一下,给父类nn.Module初始化一下。(Python的基础知识)==
神经网络深度学习其实==主要就是学习卷积核里的参数,像别的不需要学习和改变的,就不用放进去==。
forward为前向传递函数,这个函数必须写。真正执行数据的流动
这个Net的Class定义主要要注意两点
第一:是注意前后输出通道和输入通道的一致性。不能第一个卷积层输出4通道,第二个输入6通道,这样就会报错。
第二:它和我们常规的python的class还有一些不同。如何使用这个net
先定义一个Net的实例(毕竟Net只是一个类不能直接传参数,output=Net(input)当然不行)net=Net()
假设你已经有一个要往神经网络的输入的数据“input”,这个input应该定义成tensor类型 output=net(input)
2.损失计算
定义损失函数 以loss为例 将类进行实例化compute_loss=nn.MSELoss()
之后就可以把你的神经网络的输出,和标准答案target传入进去:loss=compute_loss(target,output)
3.反向传播
loss.backward()
如果是自己的定义的loss(比如你就自己定义了个def loss(x,y):return y-x )这样肯定直接backward会出错。所以应当用nn里面提供的函数。
如果想要定义自己的loss,必须也把loss定义成上面Net的样子,也是继承nn.Module,把传入的参数放进forward里面,具体的loss在forward里面算,最后return loss。__init__()就空着,写个super().__init__就行了。
4.更新参数
在Net定义完以后,需要写一个优化器的定义
以SGD为例:
1 | from torch import optim |
优化器也是一个类,先定义一个实例optimizer,然后之后会用。注意在optimizer定义的时候,==需要给SGD传入了net的参数parameters,这样之后优化器就掌握了对网络参数的控制权==,就能够对它进行修改了。传入的时候把学习率lr也传入了。
在每次迭代之前,先把optimizer里存的梯度清零一下(因为W已经更新过的“更新量”下一次就不需要用了)·optimizer.zero_grad()
在loss.backward()反向传播以后,更新参数: optimizer.step()

处理流程
数据处理
https://blog.csdn.net/qq_37568167/article/details/105841129
数据包含以下四个子模块:
- 数据收集: img,label 原始数据和标签
- 数据划分: train训练集,valid验证集,test测试集
- 数据读取: DataLoader
1) Sampler(生成index);
2) Dataset(读取Img,Label); - 数据预处理:transforms
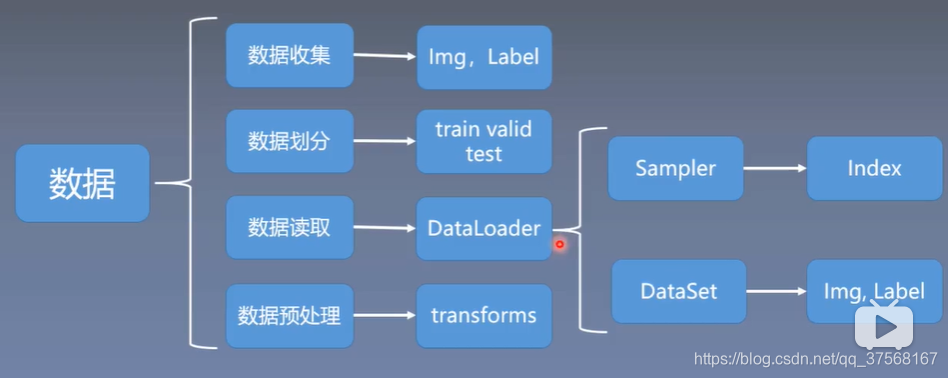
DataLoader
torch.utils.data.DataLoader 功能:构建可迭代的数据装载器
参数:
- dataset:Dataset类,决定数据从哪里读取及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch、Iteration、Batchsize
- Epoch:所有训练样本都已输入到模型中,称为一个epoch
- Iteration:一批样本输入到模型中,称之为一个Iteration
- Batchsize:批大小,决定一个Epoch有多少个iteration
1 | 样本总数:80 batchsize:8 |
1 | 样本总数:87 batchsize:8 |
Dataset
torch.utils.data.Dataset 功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且要复写函数 getitem()
- __getitem__() :接收一个索引,返回一个样本及标签
数据标准化与归一化
https://blog.csdn.net/weixin_36604953/article/details/102652160
归一化
Normalization
是对原始数据的线性变换,使结果值映射到[0 - 1]之间。
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
归一化后的图像与原始图像存储的信息是一样的,不会有信息损失
为什么进行归一化
https://www.zhihu.com/question/293640354
灰度数据表示有两种方法:
uint8类型 double类型
其中uint8类型数据的取值范围为 [0,255],而double类型数据的取值范围为[0,1],两者正好相差255倍。
对于double类型数据,其取值大于1时,就会表示为白色,不能显示图像的信息,故当运算数据类型为double时,为了显示图像要除255。
标准化
Standardization
给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将数据变换为均值为0,标准差为1的分布,并非一定是正态的。
转化函数为:
其中
代码分析
data_loader.py
定义以下多个图片变换的操作
ResacleT
1 | class RescaleT(object): |
Rescale
1 | class Rescale(object): |
CenterCrop
1 | class CenterCrop(object): |
RandomCrop
1 | class RandomCrop(object): |
ToTensorLab
问题记录
报错
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB
https://blog.csdn.net/qq_29134801/article/details/102640138
IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python
https://blog.csdn.net/chen645096127/article/details/94019443
with torch.no_grad()
https://blog.csdn.net/u014229742/article/details/110629886
不使用with torch.no_grad():可以进行梯度反传等操作。
只是想要网络结果的话就不需要后向传播 ,如果你想通过网络输出的结果去进一步优化网络的话 就需要后向传播了。
使用验证集的时候,我们只是想看一下训练的效果,并不是想通过验证集来更新网络时,就可以使用with torch.no_grad()。
torch.cat()问题
https://www.cnblogs.com/JeasonIsCoding/p/10162356.html
torch.cat()按维度进行拼接
此处举例hx = self.relu6d_1(self.bn6d_1(self.conv6d_1(torch.cat((hbg,h6),1))))
即7x7进行拼接
1 | print(hbg.shape) |
按通道进行拼接
拼接后通过卷积(512个kernels)将1024通道数变为512提取特征
进行后续操作
数据集
https://bbs.cvmart.net/articles/410/xian-zhu-xing-fen-ge-jian-ce-de-shu-ju-ji-hui-zong
| DATASET | NUM | STATUS |
|---|---|---|
| SOD | 300 | √ |
| DUT-OMRON | 5168 | √ |
| MSRA-10K | 10000 | √ |
| PASCAL-S | 850 | √ |
| HKU-IS | 4445 | √ |
| DUTS-TR | 10553 | √ |
| DUTS-TE | 5019 | √ |
| THUR-15K | ? | × |
| ECSSD | 1000 | √ |
| Judd | 900 | √ |
| SOC | ? | × |
| SED2 | ? | × |
- 本文标题:BASNet
- 本文作者:y4ny4n
- 创建时间:2022-03-19 21:13:28
- 本文链接:https://y4ny4n.cn/2022/03/19/BASNet/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!