基于mirai和graia框架的机器人搭建

一直想搭建一个bot实现一些功能,该bot基于mirai机器人框架和graia搭建,参考sagiri-bot功能实现。自己随便写写,这篇文章主要记录一下报错信息和心路历程。
更:考研回来了,重写了之前的bot,见船新版本。
基本搭建
mirai部分
基于mirai框架,需要下mirai-console和配置mirai-api-http
启动mirai-console需要装自启动mirai-console-loader,这边github太慢了,直接导入gitee仓库。
给服务器装一下Java环境
1 | java.lang.UnsupportedClassVersionError: org/zjh/openlayersdemo/OpenlayersdemoApplication has been compiled by a more recent version of the Java Runtime (class file version 55.0), this version of the Java Runtime only recognizes class file versions up to 52.0 |
这边装的java8.. 需要重装java11
1 | java.lang.NoSuchMethodError: net.mamoe.mirai.utils.MiraiLogger$Companion.setDefaultLoggerCreator(Lkotlin/jvm/functions/Function1;)V |
解决:.\mcl —update-package net.mamoe:mirai-core-all —channel nightly
重新运行mcl 启动mirai-console
将mirai-api-http的jar文件拖入plugins
配置生成的setting.yml 文件
重新启动console
配置sagiri-bot个人信息
报错原因:在使用oracle的JDK时,JAR包必须签署特殊的证书才能使用。
使用openJDK或者非oracle的JDK,这样就可以绕开证书的限制。
所以重装了java环境,卸载了原有java11环境,使用yum安装了openjdk,将/etc/profile配置文件中的环境变量更改为openjdk安装目录/usr/lib/jvm/xxx,source使之生效
虽然报错解决了,但对登录不上去这个问题没什么改变…
在mirai-console登录qq报错
1 | 2021-01-01 16:26:05 E/main: Failed to init MiraiConsole. |
最开始报错是不支持滑动验证,根据文档提示修改协议为PAD后
输入验证码登录,若账号密码验证码不正确则报错网络环境问题;若都正确报错以上信息…问题772
已解决,更改协议为WATCH后,验证登录即可
至此mirai部分配置完成,启动需要graia
graia部分
python3 sagiri_bot.py报错
1 | File "/usr/lib64/python3.6/functools.py", line 477, in lru_cache raise TypeError('Expected maxsize to be an integer or None') TypeError: Expected maxsize to be an integer or None |
装了SDK
1 | pip install graia-application-mirai |
发现不仅是import graia.broadcast产生的报错,后边调库的时候还有很多别的报错,经过很久很久的搜索,终于在graia project的issue下面找到了原因所在
由于pip使用阿里源的问题,直接下载了graia-application-mirai 0.0.6的版本 会出现很多报错
$ pip install -i https://pypi.python.org/simple graia-application-mirai==0.1.0
更改为0.1.0版本不再报错
这次又有了船新报错
1 | from __future__ import annotations |
从Python 3.7才可以开始导入__future__``annotations
服务器centos自带3.6 重装3.7….. 之前给ubuntu做过升级
装好后更改软连接,使pip3与python3指向3.7
1 | ln -s /usr/local/python3/bin/python3 /usr/local/bin/python3 |
重装第三方库
好家伙,还有什么报错是我没遇到的…
报错原因:问题出在pydantic包,graia.broadcast.entities.event.EventMeta类继承自pydantic中的ModelMetaclass类,在pydantic版本是1.7.1的情况下该类貌似添加了一个空的slots属性,导致子类都无法进行self的赋值。把pydantic包回退到1.6.1版本问题解决。
pip3 install pydantic-1.6.1
重新运行bot.py
至此,机器人实现了第一次会话 芜湖~

编写代码再用winscp上传到服务器太过费劲(关键是老断,vim也比较麻烦。装了vscode的插件sftp,服务器建立相同文件名文件夹,右键直接upload即可。芜湖~
运行sagiri_bot.py 报错无graia.scheduler模块
装后broadcast版本问题发生冲突…
1 | graia-application-mirai 0.1.0 has requirement graia-broadcast<0.0.6,>=0.0.5, but you'll have graia-broadcast 0.5.3 which is incompatible. |
graia-application-mirai 0.1.0 需要 broadcast<0.0.6,>=0.0.5
但graia-scheduler需要broadcast<0.6.0,>=0.5.3
安装scheduler后broadcast版本为0.5.3
解决:搜索后发现文档更新
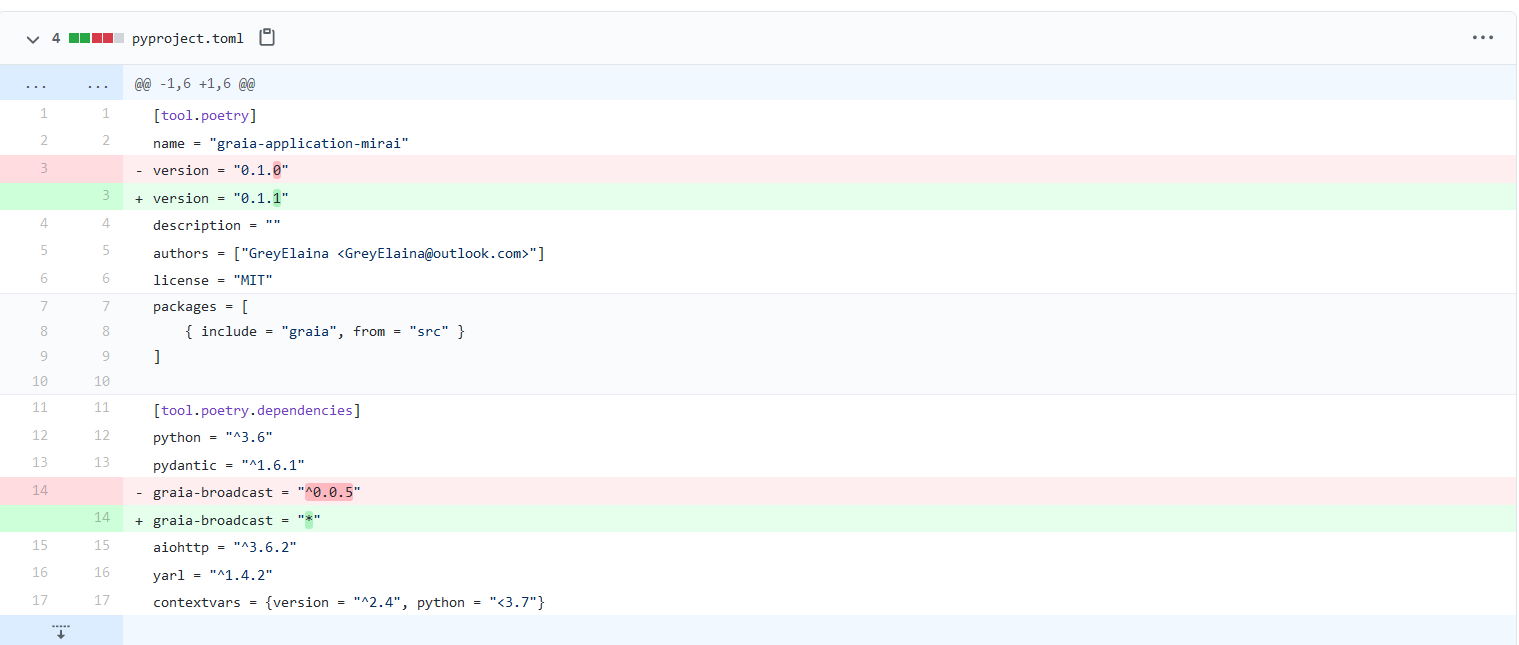
更新到graia-application-mirai==0.1.1后,broadcast版本可以兼容
最终解决: 看github上作者commit的历史版本找了个合适的graia-application-mirai 0.11.0 ,可以兼容并运行(突然发现graia-application-mirai 都更到0.14.0了
今天被冻结了呜呜呜呜,又是拼命解冻的一天
模块编写
服务器服务后台悬挂(关闭终端不影响)
1 | nohup python xxx.py & |
钉钉接口
可以实现从后台导出日报数据,但必须是企业管理员权限
分析河北师大的组织架构与我创建的APItest映射
河北师范大学(APItest)
2019级群(子部门)
辅导员(子部门群主test)
班长(子部门管理员)
经测试,所有人都可创建表,并对自己创建的表有管理权限
子部门群主和管理员都没有权限登录后台(估计要河北师范大学的管理员
所以不考虑从后台导出表格,可以考虑下ocr…哎
疫情模块
调用新浪接口
https://interface.sina.cn/news/wap/fymap2020_data.d.json
返回数据后decode 此时为json格式的字符串
json.loads() 将json格式数据解码为python对象(即字典),再对数据进行处理
六级词汇模块
六级词汇字典上传到服务器后中文乱码
开始以为是vim编码的问题,但是py的问题
读文件r读字符串utf8无法解码,rb以二进制形式读进来后需要再解码进行转换成str 解码用gbk就可以显示了(不知道为啥utf8不行 菜鸡の迷惑
奥 txt是ANSI编码的,GBK属于ANSI之中的,在ANSI的国际通用集,GBK是专门来解决中文编码的,那没事了TnT
bilibili推送模块
三个思路
× 1.搞了bilibili的json
哔哩哔哩小程序 最终分享地址为url参数中的内容,需要每日分享获取其url 较难自动实现(后面的随机值应该为哔哩哔哩小程序自动生成)
手机端不能显示 PC端可以
这个格式是Bilibili小程序的 url问题解决不了 呜呜呜呜
× 2.申请自己的小程序 最终直接访问 bilibili.com 涉及开发了 草
√ 3.找其他小程序的跳转功能 json源码 试了几个跳不了 草
歪日 终于成了 google永远滴神 找了一个可跳转的小程序 唯二不足就是图片白搞了&BV号得手动输入(待优化)
然后设成定时了
论文推送
知乎的非官方api都用不了了,增加了反爬机制。
最初使用requests包请求界面,报403..原来是因为没加headers(没有设置headers请求头,被服务器拦截,一般情况下设置user-agent即可。)
后来使用selenium库 模拟打开浏览器,寻找元素并定位
一直报错找不到元素,很疑惑 加个sleep就好了 一部分没加载出来
找到对应标题的超链接 获取元素属性get_attribute()
定位使用的是find_element_by_link_text
得到对应文章url 推送即可
问题是如何部署在centos上,服务器无GUI使用selenium
参考链接:https://blog.csdn.net/shilaike2/article/details/102595228
安装xvfb Xvfb是一个实现了X11显示服务协议的显示服务器。 不同于其他显示服务器,Xvfb在内存中执行所有的图形操作,不需要借助任何显示设备
还需增加几个options
1 | chrome_options =webdriver.Options() |
又是面向百度编程的一天
船新版本
以上为大二时瞎捣鼓的结果,因为考研耽搁了很长一段时间。有了上述基础,终于可以在考研后进行愉快的探索~
这一次,带着我的船新bot卷土重来!~
功能展示
抽卡功能
卡池内包含恋与制作人截止22年所有羁绊,包括进化前后的两张卡面,各稀有度概率分别为:
SP—1% SSR—2% \ER—7% SR—10% R—80%
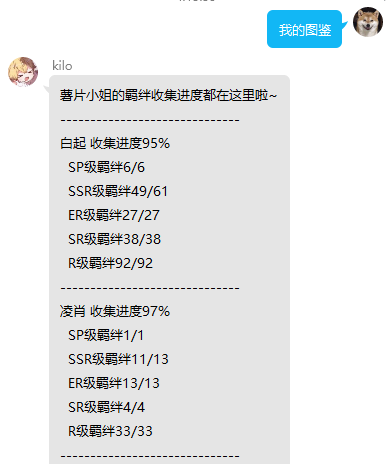
连接数据库记录群聊内每个成员的抽卡记录及所获得的卡面,当出现未收录时显示new标。快速十连界面和羁绊界面为实时绘制,若羁绊较多则响应速度慢,后续考虑改进。
usage:回复 抽卡 进行单次获取羁绊
usage:回复 抽卡十连 进行十次获取羁绊 以十张卡面大图形式返回 耗时10s左右

usage:回复 快速十连 进行十次获取羁绊 以缩略图单张形式返回 耗时2s左右
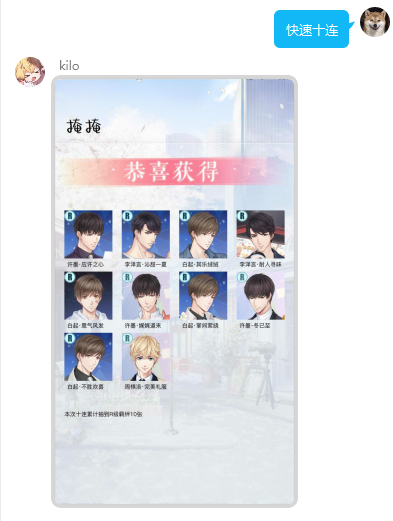
usage:回复 我的羁绊 查看已获得的羁绊

usage:回复 我的图鉴 查看羁绊的收集进度
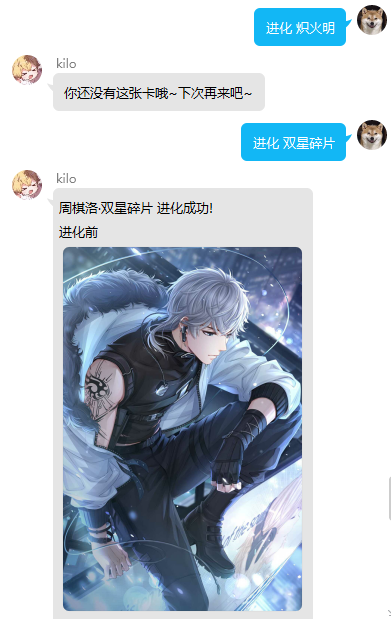
usage:回复 进化+羁绊名 进化到羁绊的第二张卡面(只能进化自己拥有的羁绊)
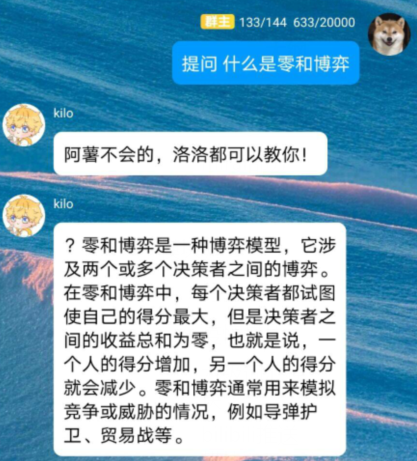
提问功能
usage:回复 提问+问题 即可发出提问,问题发出后kilo应答即为请求成功,需耐心等待数秒
若返回1分钟后再试提示,则表明请求次数频繁,1分钟后kilo会提示再次请求
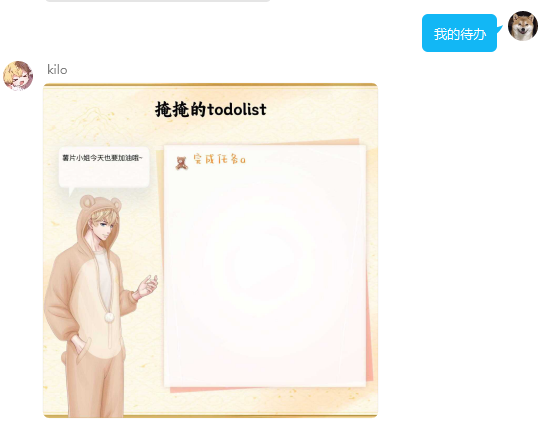
TodoList功能
该功能的左侧立绘及对话框每次调用随机选择进行绘制,若添加任务过多至上限,则删除已完成待办。若全部未完成,则不能再继续添加。
usage:回复 添加待办+需要完成的任务 进行单次添加
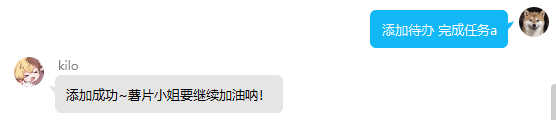
usage:回复 添加待办+任务1/任务2/任务3 进行批量添加
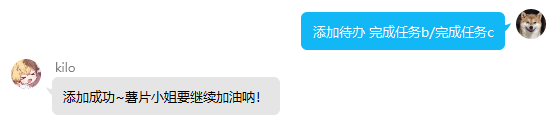
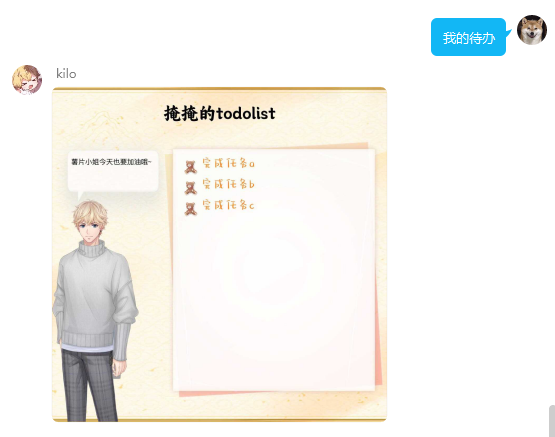
usage:回复 删除待办+需要删除的任务 进行单次删除,批量删除用法同上
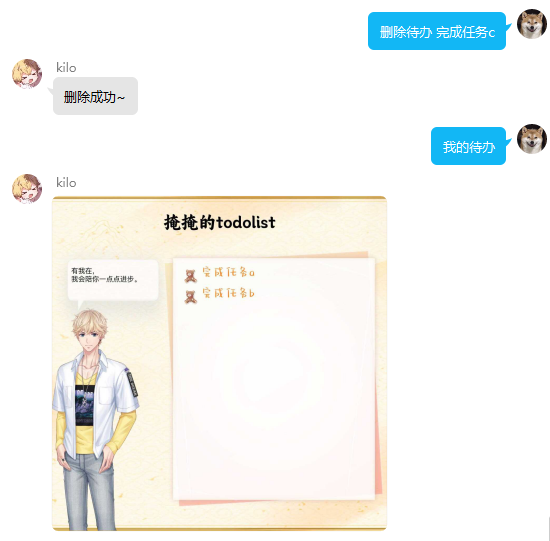
usage:回复 完成待办+完成删除的任务 进行单次完成,批量完成用法同上
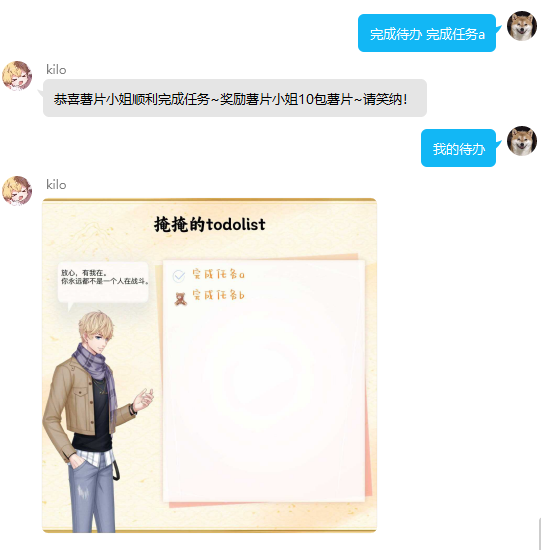
usage:回复 清空待办 即可删除所有待办

usage:回复 我的待办 查看当前TodoList的记录
调教功能
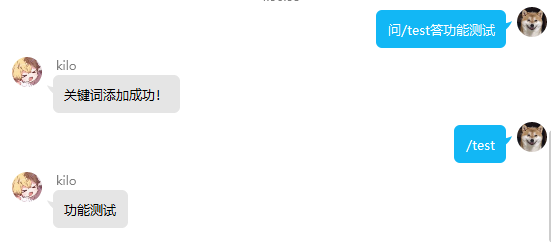
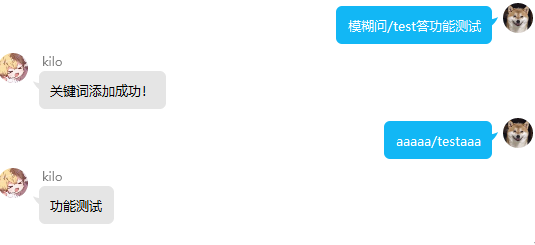
关键词匹配模式有三种: 全匹配,模糊匹配,正则匹配
全匹配:输入全等于关键词,模糊:输入中包含关键词,正则:输入满足正则表达式
该功能支持除文字外的表情包、表情、图片等文件格式。
usage:回复 问关键字答xxx 触发全匹配 例:问洛洛答在呀
usage:回复 模糊问关键字答xxx 触发模糊匹配 例:模糊问洛洛答在呀
usage:回复 正则问正则表达式答xxx 触发模糊匹配 例:正则问^.*洛洛$答在呀
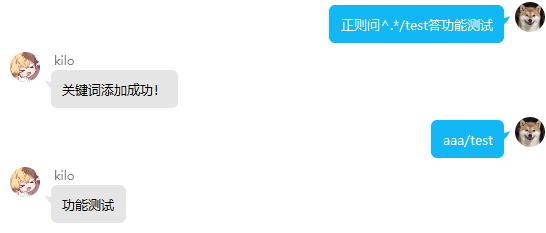
语音合成功能
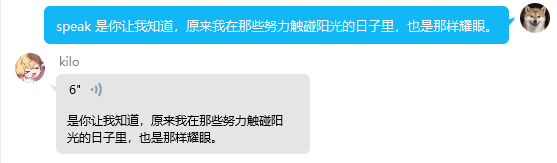
该功能通过调用使用角色语音数据训练好的vits模型进行实时tts推理,并以QQ支持的语音文件格式进行发送,结合语音标注的功能,可以简陋实现与角色的模拟对话。
usage:回复 speak 想说的话 返回合成的角色语音
语音标注功能
语音标注可以视作是调教功能的一部分(但不成熟qaq),由于kilo语音数据繁多且种类复杂,开发的薯片小姐无法短时间内完成数据标注
本功能涉及kilo的语音数据标注,请使用之前慎重考虑,确保添加内容有意义并符合应用场景和人物设定
usage:回复 语音标注 kilo会返回语音库中任意一条语音,并返回其编号和文本
usage:回复 问/模糊问/正则问关键字答[wav语音编号] 添加关键字用法同调教功能
发展构想
bot说话风格参数设置:通过不同风格参数值的调整形成不同的话术风格。
语言对话模型需要用不同数据集来训练,可以通过网络小说中不同角色的台词进行提取,通过辅助性的样本训练将原始模型拉到不同方向。
基本路线: 在chatgpt的基础上微调模型风格参数或重新训练赋予人格或者将chatgpt输入通过另一个风格转换的自然语言处理模型进行转换输出 赋予使用语言对话模型的Bot特定人设 并生成对话
使用语音合成技术,进行训练并生成语音实现聊天机器人的情感需求。
需解决的问题:说话风格迁移模型 上下文联系
开发小记
解决抽卡速度响应过慢问题
排查到是发送图片过大(MB),隔壁群为KB 响应速度差10s
法1 想到图片压缩 使用opencv 粗暴的使用
1 | img=cv2.imread(card_path) |
进行压缩,发送速度提高,但面临无法查看原图及高清图片被覆盖的情况。如果写到另一个文件夹,存储位置翻倍且要进行判断是否已经存在。
如果在本地压缩后上传所有图片,费时费力且opencv读写文件不能出现中文。想到有没有方法可以直接进行图片压缩发送而不保存到本地
法2 了解到imencode:将图片格式转换(编码)成流数据,赋值到内存缓存中;主要用于图像数据格式的压缩,方便网络传输。
https://blog.csdn.net/weixin_34910922/article/details/117537384
1 | img=cv2.imread(card_path) |
对图像进行压缩同时,转换为二进制数据。正好graia支持使用字节流发送图片,实现无保存压缩。
卡面小图的截取问题
本来图省事,想着能不能自动识别一下,发现识别概率太低了
https://www.freesion.com/article/9367146372/
https://blog.csdn.net/qq_42951560/article/details/111831797
1 | import cv2 |
由于opencv中没有动漫的2D人像识别,下载lbpcascade_animeface.xml文件到所在目录
detectMultiScale参数:
scaleFactor–表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;
minNeighbors–表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,
minSize和maxSize用来限制得到的目标区域的范围。
根本没几张图能用,还必须是正脸,只能用于R卡,还是手动吧。
批量语音转文字
通过批量语音转文字服务为角色语音数据集标注,用于训练。
现有平台:
- 科大讯飞、知意等付费平台
- 剪映、Pr等剪辑如案件生成字幕
- 百度云、腾讯云等国内接口
- Google、IBM、Bing等国外接口
1)使用讯飞语音识别
语音听写 https://www.xfyun.cn/services/voicedictation
语音转写https://www.xfyun.cn/services/lfasr#anchor4503211
API文档 https://www.xfyun.cn/doc/asr/voicedictation/API.html
坑:demo中鉴权401问题 https://blog.csdn.net/laihongfeng/article/details/123116826 urllib的urlencode将date中空间编码为+号而非%20造成Unauthorized错误 url = url.replace('+','%20')替换解决
解决后可以建立连接 但是识别不出来 可能由于音频文件格式或者采样率问题
2)使用百度云语音识别API https://cloud.baidu.com/product/speech/asr
API文档 https://ai.baidu.com/ai-doc/SPEECH/Vk38lxily
依旧识别不出来
3)使用腾讯云
API Explorer测试成功后在本地安装 tencentcloud-sdk-python
需要先发送识别请求 再查询识别结果
API Explorer https://console.cloud.tencent.com/api/explorer
API文档 https://cloud.tencent.com/document/product/1093/37823
教程 https://blog.csdn.net/alv2888/article/details/124224020
完成一个发送请求和识别后,进行批量处理
修理小记
原因:出现code45报错 大规模封控 需要增加第三方签名服务
mirai提供了协议修复插件 用于对接第三方签名服务
https://github.com/cssxsh/fix-protocol-version
安装并配置第三方签名服务
https://github.com/fuqiuluo/unidbg-fetch-qsign
部署教程 https://github.com/fuqiuluo/unidbg-fetch-qsign/wiki/%E9%83%A8%E7%BD%B2%E5%9C%A8Linux
并配置该服务的config.json
!踩坑 不要把该签名服务的端口和mirai端口开在同一个 会出现占用情况
在该文件夹下启动 bash bin/unidbg-fetch-qsign —basePath=txlib/8.9.68
注意:需要手动从apk安装包的lib/arm64-v8a目录中提取出libfekit.so 、libQSec.so 文件并存放至一个文件夹,然后使用--basePath指定该文件夹的绝对路径
从该项目issue下发现有一键包提取好的文件 可以选择对应版本直接拖过来
https://github.com/rhwong/unidbg-fetch-qsign-onekey
启动bash bin/unidbg-fetch-qsign --basePath=txlib/8.9.63
或后台运行 nohup bash bin/unidbg-fetch-qsign --basePath=txlib/8.9.63 &
注:服务器重启后需重新运行第三方签名服务
fix-protocol对接
确保第三方签名服务可以正常运行后
首先更新修复插件版本fix-protocol-version 从1.3.0-1.11.0
下载release中的 mirai2.jar 放到 plugins ,重启 Mirai Console 即可
修改配置文件(KFCFactory.json),根据版本指定第三方签名服务
启动后发现mirai中ANDROID_PHONE协议的版本为8.9.58 与第三方签名服务中版本不符 缺少8.9.58配置信息 会强制退出控制台
在config/Console/AutoLogin.yml中先取消自动登录
进入mirai控制台后 拉取更新协议版本
protocol sync 在线同步协议
protocol fetch 在线获取协议
将mirai中ANDROID_PHONE协议的版本为8.9.63 同时启动对应版本的第三方签名服务
再设置回自动登录 此时需要重新进行滑块验证 使用edge进入F12重新抓取获得tickets 完成mirai登录
启动bot主程序
poetry run python3 bot.py
登录不久后掉线
回溯mcl下nohup.out发现
1 | 2023-09-20 16:27:00 E/UnidbgFetchQsign: xyz.cssxsh.mirai.tool.KFCStateException: unidbg-fetch-qsign 服务异常, 请检查其日志, 'Uin is not registered.' |
报错信息显示 ‘Uin is not registered.’
疑似token过期需要刷新 或者 没有使用时没有注册实例
见readme(还没看懂) https://github.com/fuqiuluo/unidbg-fetch-qsign/blob/master/refresh_token/README.md
sign的token会过期(过期时间在1小时左右,建议每隔30~40分钟请求刷新token)
目前只在config.json中修改auto_register参数为true,启用自动注册实例功能。
实时运行成功,待后续等待时间后报错观察。
- 本文标题:基于mirai和graia框架的机器人搭建
- 本文作者:y4ny4n
- 创建时间:2023-02-05 09:19:22
- 本文链接:https://y4ny4n.cn/2023/02/05/bot/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!