
vits语音合成

记录一次vits模型训练并部署到qq-bot的踩坑历程
lab1
梦开始的地方:https://www.bilibili.com/video/BV1w84y1n7Ei/
VITS原版:https://github.com/jaywalnut310/vits
VITS(CjangCjengh版):https://github.com/CjangCjengh/vits
详细教程:https://www.bilibili.com/read/cv21153903
符华模型:https://www.bilibili.com/video/BV1zy4y197Tz/
派蒙模型:https://www.bilibili.com/video/BV16G4y1B7Ey/
加载预训练模型:https://www.bilibili.com/video/BV1yj411N7rt/
零基础炼丹秘籍 - 为自己喜爱的角色训练TTS(文字转语音)模型:https://www.bilibili.com/read/cv17826415
零基础炼丹 - vits版补充: https://www.bilibili.com/read/cv18357171
预设加载预训练模型的vits:https://github.com/rotten-work/vits-mandarin-windows
MoeTTS:https://github.com/luoyily/MoeTTS
MoeGoe:
数据集准备
格式处理
wave查看采样率
1 | import os |
scipy查看采样率、声道数、pcm位
1 | import os |
pydub 修改声道数和采样率
1 | from pydub import AudioSegment |
整理所有音频数据符合单声道、22050Hz,PCM 16bit。
文本整理
提前使用腾讯云的接口实现了语音转文字 这里只需整理为固定输入格式
将数据集分为测试集和训练集分别整理
环境配置
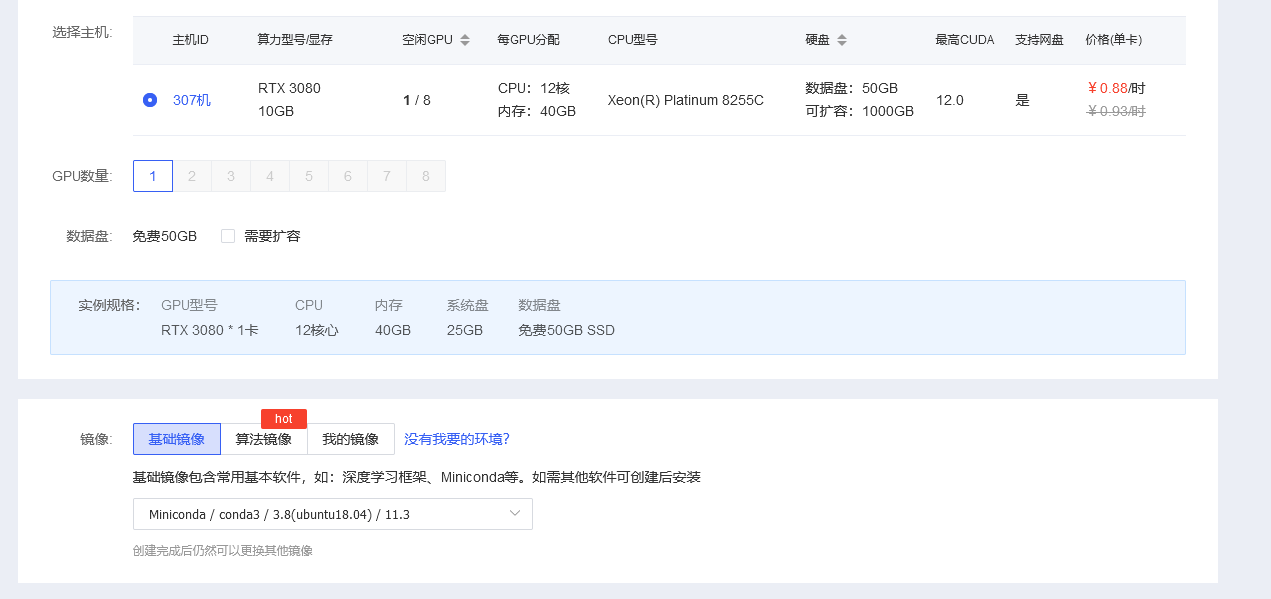
租好gpu后安装requirements中的依赖
配置文件
生成config.json
根据租的服务器显存选择合适的batch
修改cleaner为chinese_cleaner
进行预处理

训练
首先进行预训练
使用中文女声标贝进行预训练300个epoch,再在该权重模型基础上进行微调
只需按原方法将标贝的语音数据集和文本进行替换(并重新预处理生成cleaned文件)开始训练即可

RTX 3080 10GB 开始设置batch为16后内存不足 改为8
训练一个epoch大概5min
训练过程中发现2200个epoch的标贝预训练模型也无法正常说话?并且模型参数不匹配,怀疑是预训练模型的版本与MoeTTS及后面训练的模型版本冲突,故又租了个服务器,打算自己训练300epoch的标贝试试。(money—
TTS推理
MoeGoe
开始使用MoeGoe后报错,修改全英路径和删除config文件后无果,改用MoeTTS。

MoeTTS
可以加载kilo的模型,不能加载预训练的标贝模型
RuntimeError: Error(s) in loading state_dict for SynthesizerTrn:
size mismatch for enc_p.emb.weight: copying a param with shape torch.Size([50, 192]) from checkpoint, the shape in current model is torch.Size([78, 192]).
vits-gradio
kilo和标贝都参数不匹配
RuntimeError: Error(s) in loading state_dict for SynthesizerTrn:
size mismatch for enc_p.emb.weight: copying a param with shape torch.Size([78, 192]) from checkpoint, the shape in current model is torch.Size([43, 192]).
类似报错:https://www.bilibili.com/video/BV1be4y1V7g6/
使用说明:https://www.bilibili.com/video/BV1DT41127wr/
MoeSS
教程专栏:https://www.bilibili.com/read/cv22051145
需要把pth转为onxx文件 先不尝试了
co-lab在线推理
github项目:https://github.com/rotten-work/vits-mandarin-windows
https://colab.research.google.com/drive/1VWBOp3PDGNO77_xOm20yRtc4CSmsbqtb#scrollTo=2z_JvLmivPEf
突然发现前几个tts貌似都打开错方式了….
同一个模型我放到唯一能用的MoeTTS中只能发出单音节词但是上传到colab上发现500epoch已经可以说话了且效果非常好(但是标贝模型还是会出参数不匹配的error)
尝试拉到本地试一下
本地windows环境需要安装MSVC和win10SDK
然后就可以推理了
服务器部署
部署踩坑
1.poetry安装pytorch问题
https://stackoverflow.com/questions/59158044/poetry-and-pytorch
在pyproject.toml中添加以下后并poetry install
1 | torch = {url = "https://download.pytorch.org/whl/cpu/torch-1.8.0%2Bcpu-cp38-cp38-linux_x86_64.whl", markers = "sys_platform == 'linux'"} |
2.重新build monotonic alignment search
3.OSError: cannot load library ‘libsndfile.so’: libsndfile.so: cannot open shared object file: No such file or directory
依赖库librosa报错 执行yum install libsndfile
4.No module named ..
路径问题 参考引用不同文件夹下的模块 https://www.jb51.net/article/269579.htm
5.依旧是ImportError

这个一眼看出是vits模型里的文件夹和saya模块的文件夹重名了(犯过太多次错
改bot主程序saya加载部分和文件夹名
至此 可以实现vits模型tts推理接入qq-bot的模块 效果如图
并且可以随时上传新训练好的模型进行替换~
tensorboard
在autodl中使用tensorboard查看模型收敛情况
autodl默认的tensorboard的event文件保存路径为/root/tf-logs/
修改tf logs目录为模型文件夹下生成event的路径 再重启tensorboard

在autopanel中查看loss曲线
模型的收敛条件
参考: https://www.bilibili.com/read/cv6372536/
通常模型的收敛条件可以有以下3个:
loss小于某个预先设定的较小的值
模型的训练目的就是为了减少loss值,那么我们可以设定一个比较小的数值,每一次训练的时候我们都同时计算一下loss值的大小,当loss值小于某个预先设定的阈值,就可以认为模型收敛了。那么就可以结束训练。
两次迭代之间权值的变化已经很小了
每一次训练我们可以记录模型权值的变化,如果我们发现两次迭代之间模型的权值变化已经很小,那么说明模型已经几乎不需要做权值地调整了,那么就可以认为模型收敛,可以结束训练。
设定最大迭代次数,当迭代超过最大次数就停止
用得最多的方式。我们可以预先设定一个比较大的模型迭代周期,比如迭代100次,或者10000次,或者1000000次等(需要根据实际情况来选择)。模型完成规定次数的训练之后我们就可以认为模型训练完毕。如果达到我们设置的训练次数以后我们发现模型还没有训练好的话,我们可以继续增加训练次数,让模型继续训练就可以了。
tensorboard给出的loss曲线过多 一时没看懂
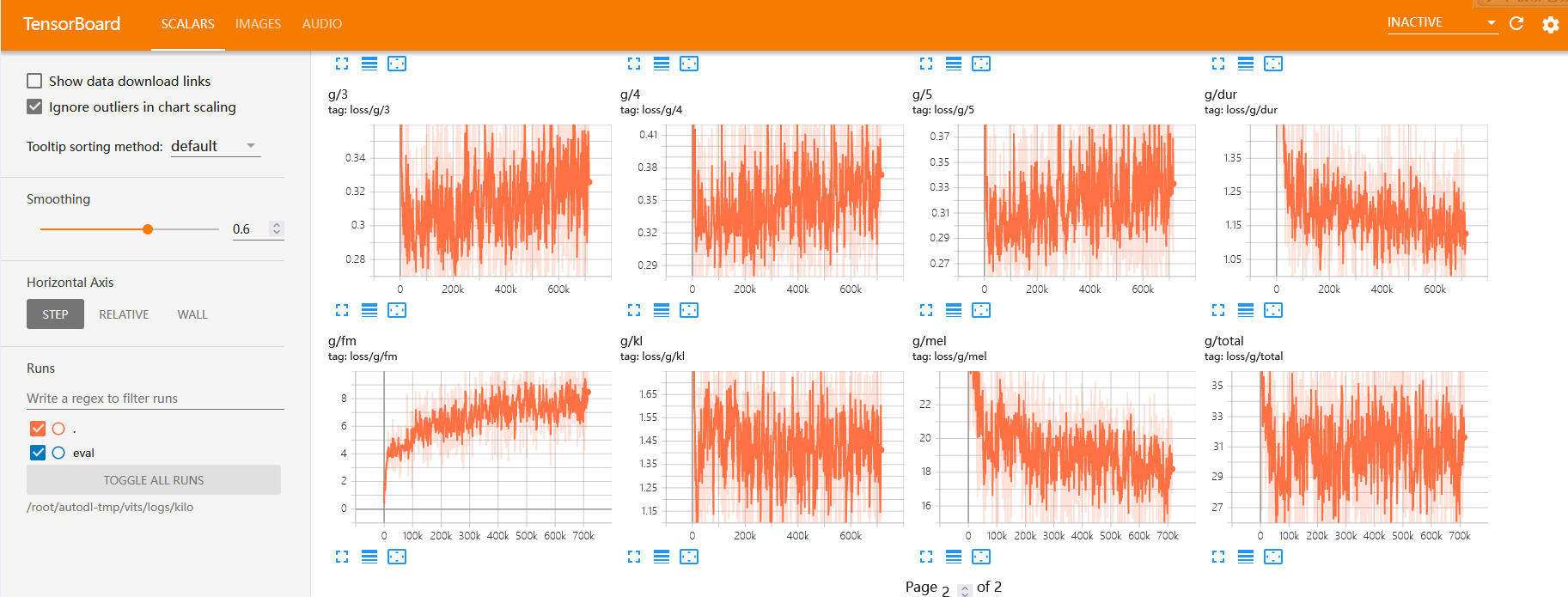
只能翻一下vits中使用的loss学习一下
vits损失函数
https://zhuanlan.zhihu.com/p/419883319
https://blog.csdn.net/zzfive/article/details/127503913
VITS可以看作是VAE和GAN的联合训练,因此总体损失为:
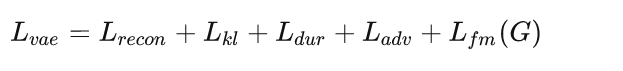
loss_gen_all = loss_gen + loss_fm + loss_mel + loss_dur + loss_kl
对抗训练过程中,判别器是常规的判别器损失结构,但是使用的是多周期判别器,由多个子判别器组成。生成器的损失,包括mel重建损失、KL散度、时长预测器损失、对抗训练生成损失以及特征图损失。
1.重建损失

loss_mel = F.l1_loss(y_mel, y_hat_mel) * hps.train.c_mel
KL散度

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 先验分布和后验分布之间的KL散度
def kl_loss(z_p, logs_q, m_p, logs_p, z_mask):
"""
z_p, logs_q: [b, h, t_t]
m_p, logs_p: [b, h, t_t]
"""
z_p = z_p.float()
logs_q = logs_q.float()
m_p = m_p.float()
logs_p = logs_p.float()
z_mask = z_mask.float()
kl = logs_p - logs_q - 0.5
kl += 0.5 * ((z_p - m_p)**2) * torch.exp(-2. * logs_p)
kl = torch.sum(kl * z_mask)
l = kl / torch.sum(z_mask)
return lloss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * hps.train.c_kl

3.对抗训练

1 | # 生成器的对抗损失,就是将生成器生成的波形经过判别器后的输出与1计算距离损失,L2损失 |
loss_gen, losses_gen = generator_loss(y_d_hat_g)

1 | # 计算对抗训练中生成波形和真实波形在判别器中间特征之间的距离损失 |
loss_fm = feature_loss(fmap_r, fmap_g)
4.时长预测器损失
时长预测器损失在模型forward函数中直接计算
loss_dur = torch.sum(l_length.float())
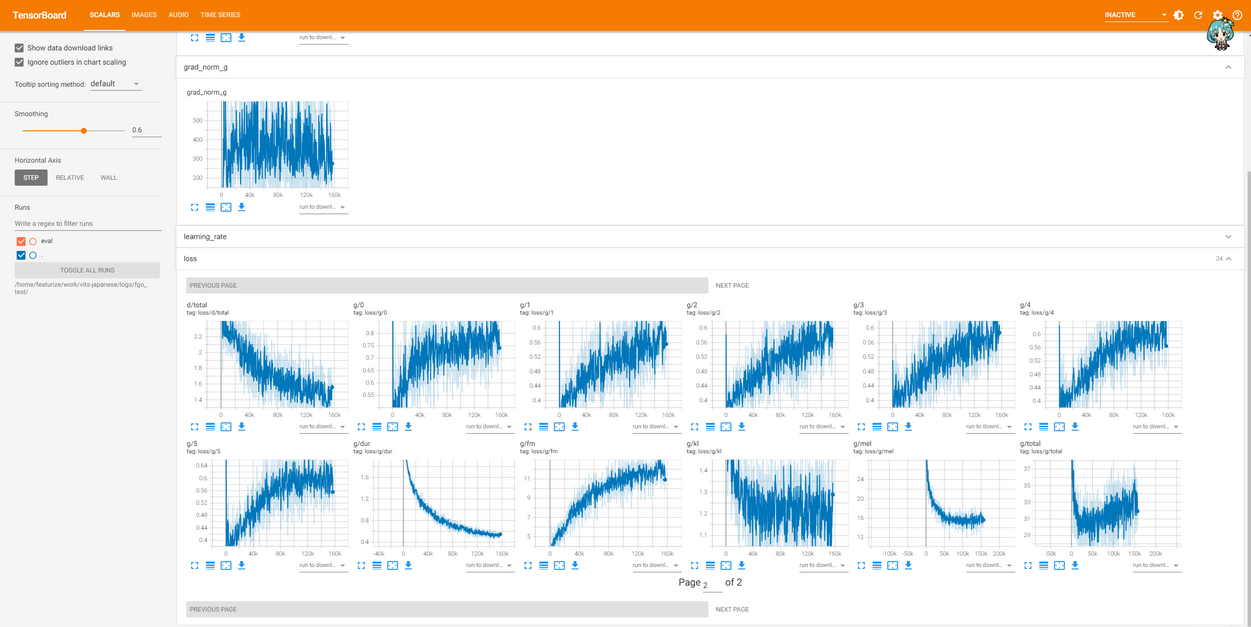
至此 可以根据tensorboard中给出的loss曲线分析模型的收敛情况
看到github vits下相关issue对loss的讨论
https://github.com/jaywalnut310/https://y4ny4nblog.oss-cn-beijing.aliyuncs.com/img/issues/14
找了别的佬训练vits时的loss参考
1.https://blog.csdn.net/qq_39182815/article/details/126312069
500条 57k步收敛
2.https://www.bilibili.com/video/BV1dY411Q7q1/
300条 1500个epoch
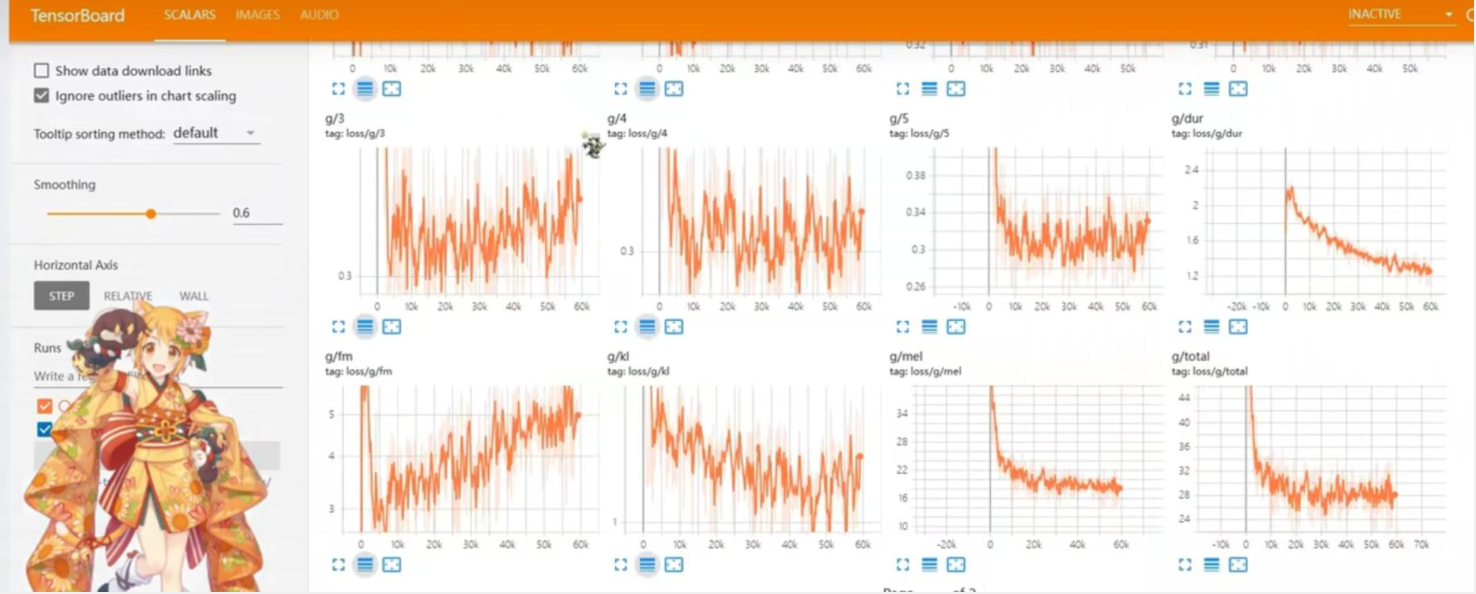
3.https://github.com/jaywalnut310/https://y4ny4nblog.oss-cn-beijing.aliyuncs.com/img/issues/14
心路历程
记录一下在训练过程中模型合成效果不好采取的一系列措施:
解决方案:
1.等机器1的2000个epoch跑完继续训练2000个(保存当前镜像
2.修改训练程序使之可以在更大显存机器上恢复训练 调高batch(打包vits文件夹
目前怀疑模型不收敛的原因是
- batch太小,epoch还不够
- 看Loss的方式有问题 了解GAN的loss变化趋势和收敛
2000epoch已跑完,效果还不是很好。租了一台3090 24G,调高了batch。但是出现了新的问题,由于我修改了bacth,global_step的值减小。模型保存文件的机制是根据global_step的值大小比较模型的新旧,导致新训练出的权重一直无法保存,且tensorboard中以global_step为横轴的折线图发生错误。
解决方案:
1.修改权重模型保存文件名,继续小batch时的计算方式保持一致(有点自欺欺人,不知道引发什么报错
2.修改参数should_auto_delete_old_checkpoints为False,保存适量的大batch模型后删除原有的(但tensorboard无法正常显示更新模型的效果,需要拉到本地进行tts推理
了解到tensorboard通过events.out.tfevents文件绘制图表。events.out.tfevents文件是训练时生成的日志文件,用于记录训练过程中的各种信息,如损失函数、准确率、图结构等。使用TensorBoard工具来可视化这些信息,分析训练效果和模型性能。
发现其命名方式中包含容器名,尝试分类之前机器和现在机器训练产生的文件后,果然更新后的折线图可以正常显示。同理新建文件夹存放之前机器的测试结果,并只在eval文件夹下存放当前机器的测试结果,测试音频也可以播放。
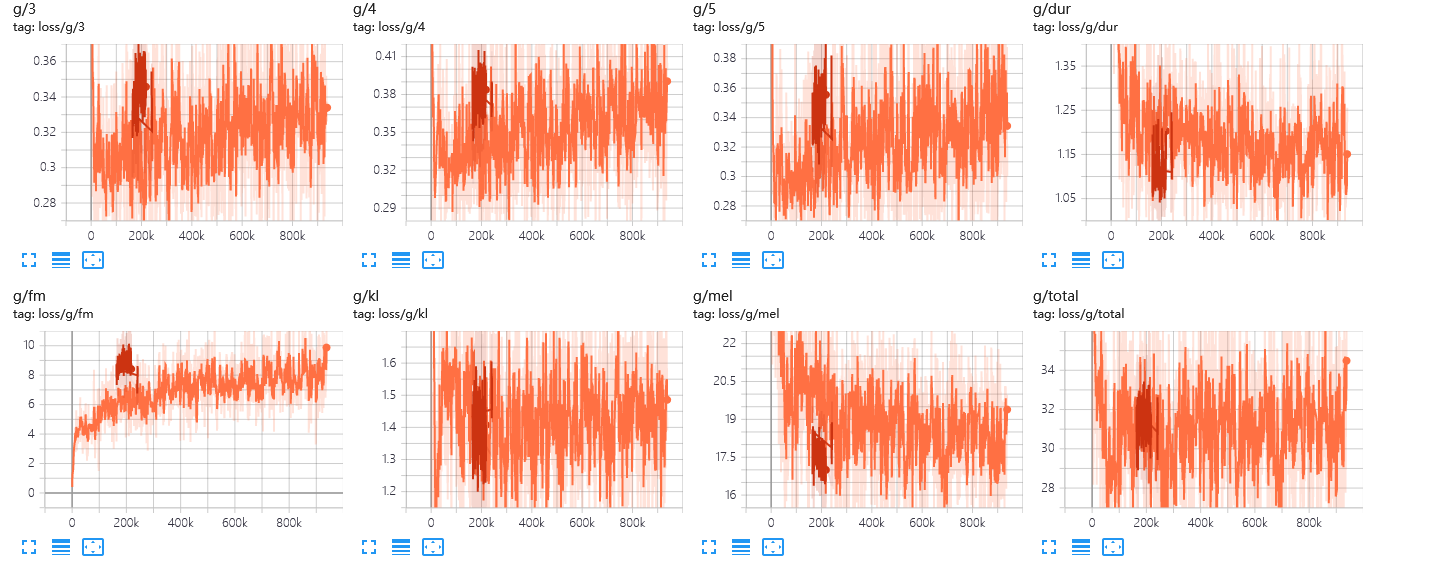
就是两个batch的global step会有重叠而非延续,不过可以凑合着看,毕竟不会改源码T^T
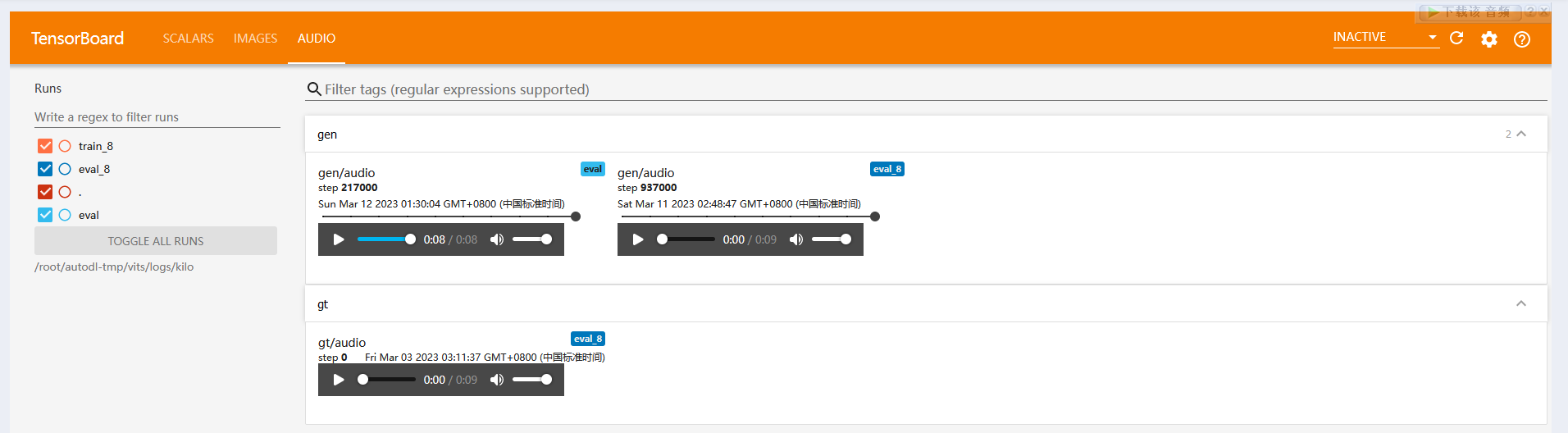
踩坑
由于原版vits没有加载预训练权重模型的模块
更换为https://github.com/rotten-work/vits-mandarin-windows
需要在config.json里增加一些字段如data_loader
- keyerror
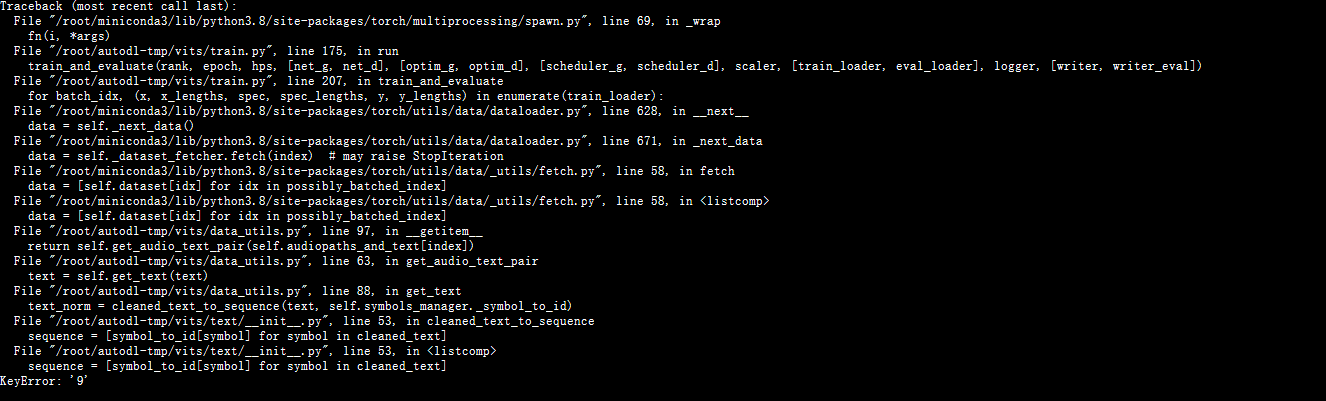
文本数据真的要好好处理,我哭死。从报错一层一层溯源发现是我的文本数据里由于包含阿拉伯数字没有解析所以出现Keyerror,已经把数据里的阿拉伯数字都改为中文了。。
2.预训练加载不进去
config配置路径问题

原因是在config.json中配置的预训练权重路径没有写绝对路径(愚蠢的我
优化器数组长度问题
valueerror: loaded state dict contains a parameter group that doesn’t match
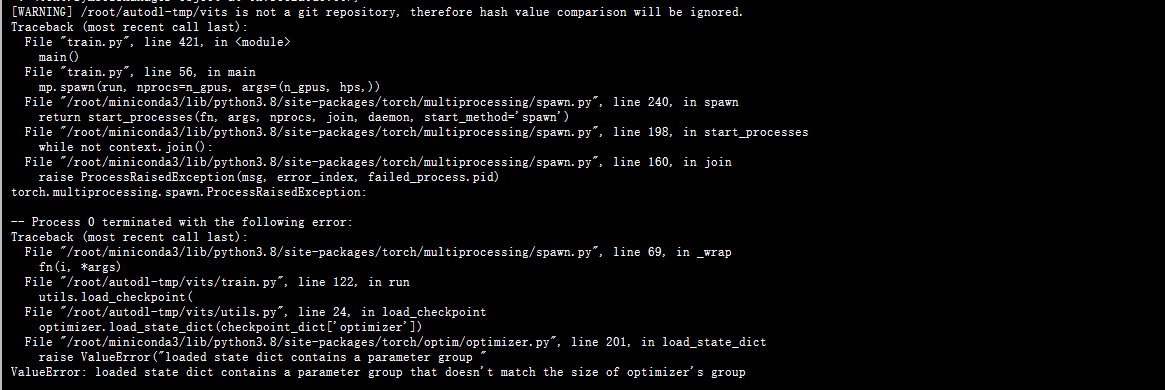
没找到解决方法,只能先注释了
3.跨地区数据拷贝
现在很想知道微调预训练模型不加载优化器对预测结果的影响(在标贝预训练模型上训练了200个epoch只能发出单音节让我很害怕…
目前猜测是batch太小了(但显存10G不允许,所以尝试一下迁移到24G显存的实例上继续训练 对比模型收敛程度
由于租的两个实例分属不同地域(我恨,没有充分吸取阿里云服务器的教训…只能通过scp实现实例间的数据拷贝(同地域可以迁移实例以及/root/autodl-nas或/root/autodl-fs实现数据共享)
https://www.autodl.com/docs/env/
在控制台查看主机2的ssh登录命令及密码,在主机1输入
scp -rP 66666 /root/autodl-tmp/xxxxx region-3.autodl.com:/root/autodl-tmp/实现主动传输
4.在新机器上恢复训练中优化器缺少初始学习率参数

https://blog.csdn.net/guls999/article/details/85695409
KeyError: “param ‘initial_lr’ is not specified in param_groups[0] when resuming an optimizer”
1 | 这个错误是由于在恢复优化器时,没有正确地指定initial_lr参数或者last_epoch参数。可以尝试以下几种方法: |
这个错误是之前注释掉优化器加载的错误造成的(utils load_checkpoint函数),
会导致每次载入检查点模型时都不加载优化器(导致模型不收敛的原因?训练过程没中断,不会重复载入模型。但可能导致中断后epoch从0开始,删除当时的注释。
lab2
视频链接:https://www.bilibili.com/video/BV1jo4y1e71H/
Github项目地址:https://github.com/Plachtaa/VITS-fast-fine-tuning
Google Colab在线训练:https://colab.research.google.com/drive/1omMhfYKrAAQ7a6zOCsyqpla-wU-QyfZn?usp=sharing
在训练lab1的过程中尝试一下另一个微调模型
上传了三百条语音数据 不需要上传标注,程序会自动标注并进行数据的预处理(去BGM 噪音 分割)
进行了30个epoch 出来一股大佐味 训练时间很短 效果不太行
(大佐味是因为多语言混训的原因和预训练模型带大佐味的问题)
解决方案:
1.拉源码到本地 修改底模为标贝 再放到服务器上跑
2.尝试增加上传数据集 并增加epoch
- 本文标题:vits语音合成
- 本文作者:y4ny4n
- 创建时间:2023-03-10 11:47:31
- 本文链接:https://y4ny4n.cn/2023/03/10/vits/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!